目次
生成AIの業務利用はさまざまな領域で拡大しています。
この記事では、書類や機器に記載された文字情報を読み取る業務に生成AIをどのように活用できるのかを解説します。
はじめに
契約書や注文書といった多種多様な書類から必要な情報を確認して、手作業で業務用システムにデータ入力する作業は、依然として多くの企業で負担となっています。こうした「情報を正確に抽出する」業務を人手で行うことは、コストと時間を要するだけでなく、人的ミス(ヒューマンエラー)のリスクも伴います。
さらに、書類に加えて、水道メーターや医療機器などの物理的な計器に表示される数値やパターンを正確に読み取り、記録する作業も現場における重要なデータ収集プロセスです。しかし、これもまた目視確認や手入力に依存しているケースが多く見られます。
これまでも、紙媒体の文字情報や、限定的な表示器の数値をデジタルデータに変換する技術としてOCR(Optical Character Recognition:光学文字認識)が活用されてきました。しかし、多様なフォーマットの書類、特に契約書のような自由記述形式の非構造化文書の読み取り精度には限界がありました。また、メーターのようなアナログ表示や、照明条件の変化、機器のディスプレイの多様性などにより、安定した数値読み取りが難しいという課題もありました。
LLMを用いたOCR
上記のような状況において、生成AIを用いたデータ収集プロセスの効率化への期待が高まっています。具体的には、文章だけではなく画像も情報源として新たに文章を生成できるマルチモーダルな大規模言語モデル(LLM: Large Language Model)をOCR領域で活用するケースが増えてきました。
マルチモーダルなLLMは、単に文字の形状や数字のパターンを認識するだけでなく、記述された文章の文脈や意味、さらには画像全体の状況を理解する能力を有しています。
LLMを用いたOCRのイメージは以下の図の通りです。
まず、契約書や計器など、情報を抽出する対象となる画像を準備しておきます。LLMには、その画像と指示文(プロンプト)を入力します。LLMへの指示文には、抽出したい情報や背景情報を入れておきます。これらの入力をもとに、LLMが指定された情報を抽出して回答します。

こうした仕組みは、例えばAWSのAmazon Bedrockのプレイグラウンド機能を使って簡単に試すことができます。
具体例がある方がわかりやすいので、実際にAmazon Bedrockのプレイグラウンド機能で名刺の画像から読み取れる情報(会社名、氏名、会社住所など)を抽出してみます。

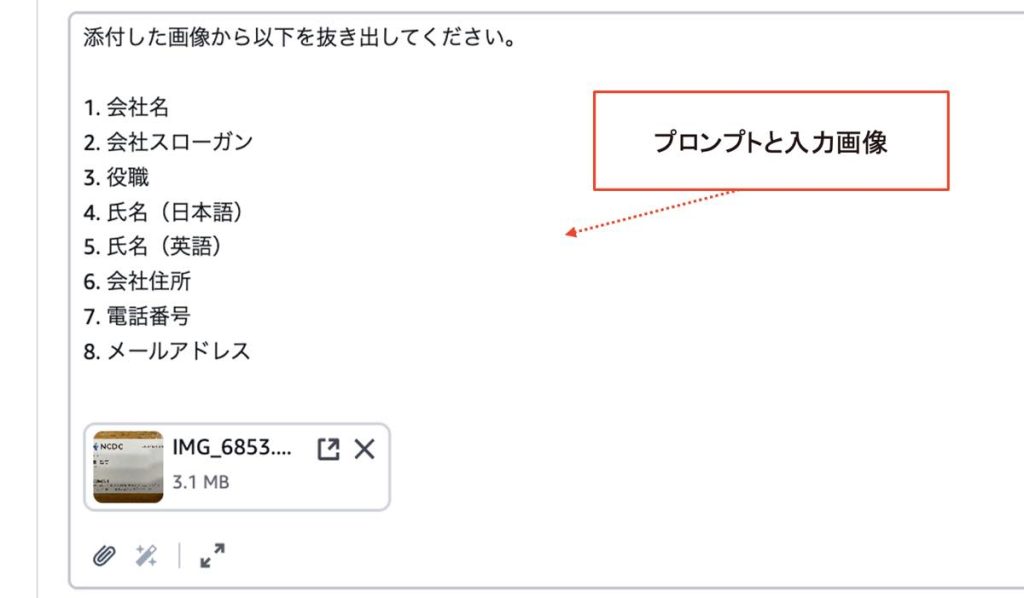
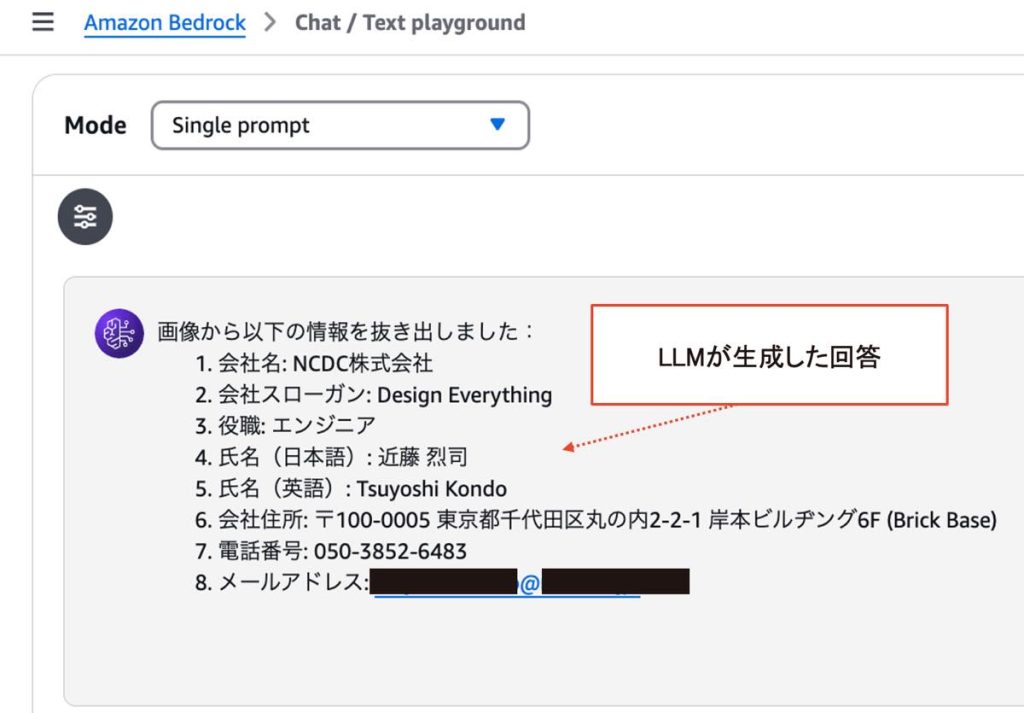
画像(名刺の写真)と指示文(添付した画像から会社名、氏名、会社住所などを抜き出すとの指示)を入力するだけで、どれが会社名でどれが氏名なのかといった構造に関する情報は一切与えなくても、対象の情報を抽出し、デジタルデータとして取得することができました。
こうした仕組みをアプリケーションに組み込む際は、抽出したデータをJSON形式など利用しやすい形で出力することもできます。
なお、Amazon Bedrockでは、入力したデータが保存されたり、LLMの学習に利用されたりすることはなく、LLMを提供しているサードパーティにデータが渡されることもないため、安心してLLMを含んだアプリケーションを開発することができます。
ChatGPTなど、他の生成AIツールを使って上記をお試しになる際は、入力したデータがLLMの学習に利用されない設定になっているかをご確認の上、お試しください。
LLMを用いたOCRの利点
LLMは大量のテキストデータで学習しており、言語の構造や意味、一般的な書類のレイアウトなど、広範な知識を事前に獲得しています。
例えば請求書の中から「合計金額」という項目を抽出する際、その文言だけでなく、記載されている位置や周囲の文脈から意味を理解することができます。そのため「総額」や「請求額」のように少し違う項目名が付いていても、文章の流れからそれが合計金額だと判断できるのです。
LLMを用いたOCRでは、単に文字を認識するだけではなく、書類や画像全体の流れと意味を理解できることで、定型化されていない(テンプレートがない)情報からでも必要なデータを抽出することができます。事前に定義された項目に限らず、文章の段落、文書中の表など、形式が固定されていない情報からも、必要な部分を読み取れるということです。
書類ごとに項目の配置が違っていても、LLMが文章の流れを理解して関係のある項目を見つけ出せるため、多様な形式の書類に対応できます。従来のOCRやAI-OCRでは、書類の種類ごとに細かい設定を用意したり、それを継続的に更新したりする必要がありましたが、LLMを用いたOCRでは、多くの場合においてそのような手間が不要になります。
事前に多くの設定をしなくてもさまざまな書類や画像のテンプレートに対応できるということは、試しに使ってみるのも容易だということを意味します。
従来は人が行っていたデータの抽出を機械で自動化する場合、従来通りの(もしくは従来以上の)精度が出るかどうかがとても重要です。容易に試せるLLMを用いたOCRであれば、期待通りの精度が出せるのかを短期間で検証できるため、実際の業務への適用可能性を迅速に見極めることができます。
LLMを用いたOCRの欠点
LLMを用いたOCRの欠点として次のものが挙げられます。以下の条件に当てはまる場合は、従来のOCRを利用した方が良いでしょう。
- 個人情報を扱う:基本的にLLMに個人情報を入力することはできません。例えば、名前や住所が記載された保険証などをLLMに入力すると回答を拒否されてしまうため、試してみることも困難です。
- インターネットに接続できない:クラウドサービスのLLMはインターネットに接続できない環境では利用できません。自分のPCなどのローカル環境にインストールできるローカルLLMを使用すればインターネット接続なしでも導入できますが、推論精度の低下や必要なリソースの準備など別の問題が生じる可能性があります。
- 時間の制約がある:LLMは一般的に入力されたテキスト全体を理解してから回答を生成するまで時間がかかります、そのため、一部の従来型OCR技術では可能なリアルタイムで結果を出力するということが難しく、時間の制約が問題になる可能性があります。
- コスト面の制約がある:LLMは多くの場合利用量に応じて費用がかかります。業務で大量の書類からデータを読み取る場合などは、コスト面の問題が生じる可能性が高いといえます。そのため、OCRの対象がテンプレートのある書類などの柔軟性が必要ではない場合、従来のOCRの方がコストを抑えられます。
従来のOCRが適したユースケース
LLMを用いたOCRの欠点を考慮し、あえて従来のOCRを使用することがあります。
例えば免許証の写真から生年月日などを読み取る場合は、LLMに個人情報を入力できないことから、LLMを用いたOCRは適しません。一方で、従来型のOCRを利用すれば免許証上の文字を読み取ることができます。
また、屋外や工場内などインターネットに接続していない環境において、低スペックなエッジデバイスを使用している場合もLLMを用いたOCRは適しません。ローカルLLMを実現しようとすると高性能なGPUやメモリが必要になります。一方で、従来型のOCRを利用すればエッジデバイス内で十分に動作させることができます。
従来のOCRとの共通の欠点
当然のことですが、従来のOCRとLLMを用いたOCRの共通の欠点として、そもそも文字を読み取ることができるような画像が用意できなければ使えないという点が挙げられます。
例えば、入力画像に光の反射による白飛びなどのノイズが大量に含まれている場合、文字の認識が困難なためデータを抽出できません。これは従来のOCRも同様のため、画像を用意する段階でカメラに偏光フィルタを付けるなどして、ノイズが含まれないように撮影する工夫が必要です。
また、LLMを用いたOCRも従来型のOCRも100%の精度ではないことは覚えておく必要があります。仮に導入の検証時にかなり高い精度がでたとしても、人によるチェックが完全に不要になるわけではありません。
OCRの導入はいきなり完全な自動化を目指すのではなく、人によるチェックの必要性を少なくし、チェック効率を高めることを目指すべきだといえます。
そもそもOCRが必要なのか検討することも大切
ここまでOCRの活用について解説してきましたが、導入を検討する前にそもそもOCRによるデータ読み取りが本当に必要か?という根本的な問いを立てることも重要です。
情報が発生する源流において、最初からデジタルで構造化されたデータ形式、あるいはQRコードのような機械可読な識別子を用いて情報を流通させるプロセスへと変更することの方が、より抜本的な効率化や精度向上につながる場合があります。具体例としては、以下のようなアプローチが考えられます。
- 取引先との請求書や注文書のやり取りをEDI(電子データ交換)に移行する。
- 社内で使用する申請書や報告書を電子フォーム化し、データベースに保存できるようにする。
- 管理対象となる物理的な資産や重要書類自体に、識別のためのバーコードやQRコードを付与し、読み取りを容易にする。
このようなアプローチは、OCR処理に伴う読み取りエラーのリスクそのものを排除し、データ入力や検証にかかるコストを大幅に削減できる可能性があります。業務プロセスのボトルネックが紙や非構造化データの処理にある場合、OCRによる効率化を目指す前に、これらの源流対策が実現できないかを検討することも大切です。
R&DやLLMを用いたサービスの開発はNCDCにご相談ください
NCDCは、新しい技術をユーザーにとって便利なかたちでシステムに活用できるかどうかを検証する段階(R&D)からのご支援も得意としています。
OCRに限らず、さまざまな先進的なIT技術に関しても技術検証から商用のシステム開発までご支援しておりますので、R&Dのパートナーをお探しの方は、ぜひお問い合わせください。