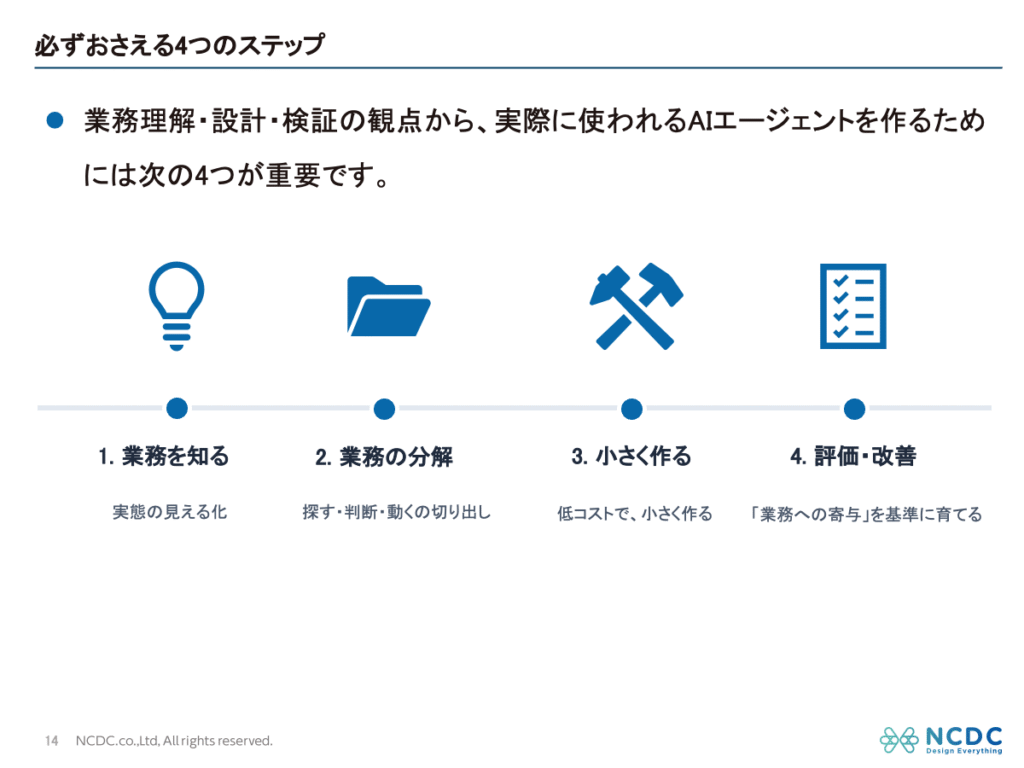
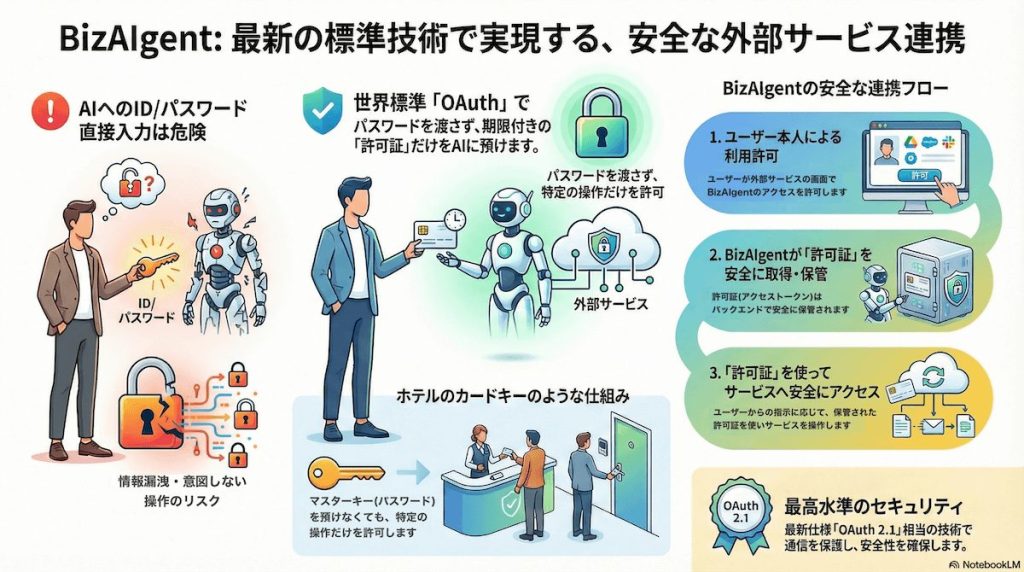
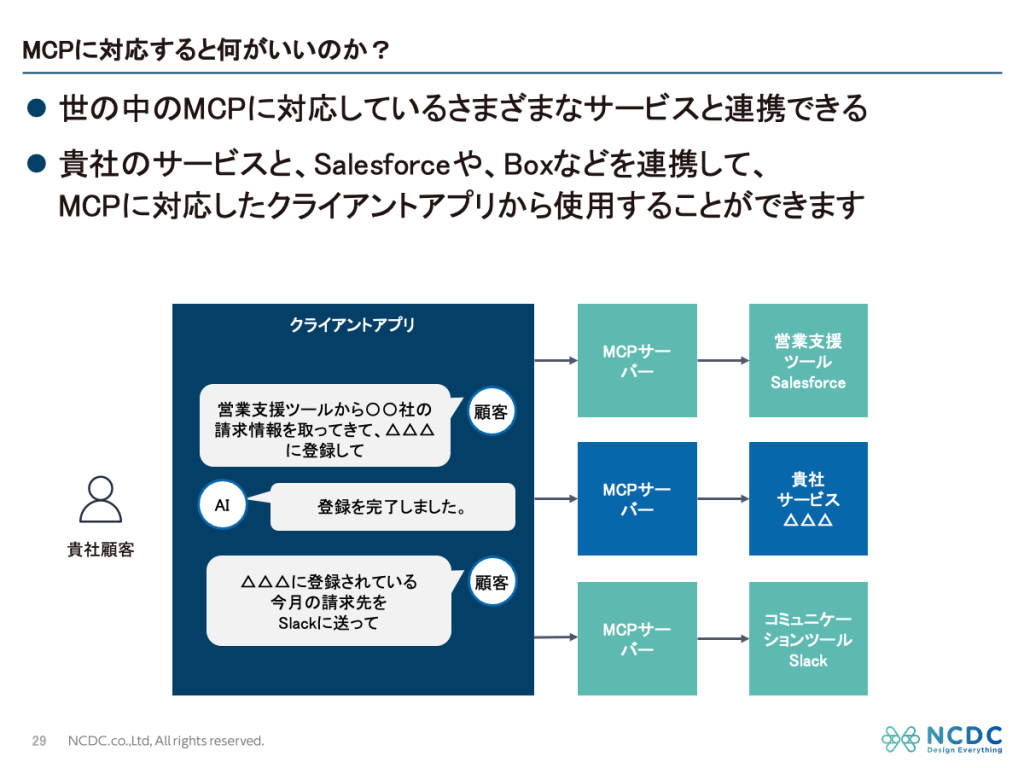
目次
多くの企業で、社内の業務データとChatGPTのような生成AIを組み合わせて活用したいというニーズが高まっています。たとえば、社内ドキュメントの確認、過去の報告書の要約、専門知識の検索など、その用途は多岐にわたります。
しかし、ただ生成AIを導入するだけでは、「期待した回答が得られない」「間違った情報(ハルシネーション)が表示される」「一部の人にしか使いこなせない」といった課題に直面しがちです。
「業務データ×生成AI」で業務効率化を成功させるには、生成AIの性能だけに頼るのではなく、業務データの準備からユーザーが使いこなせるまでの流れ全体をきちんと設計することが重要です。
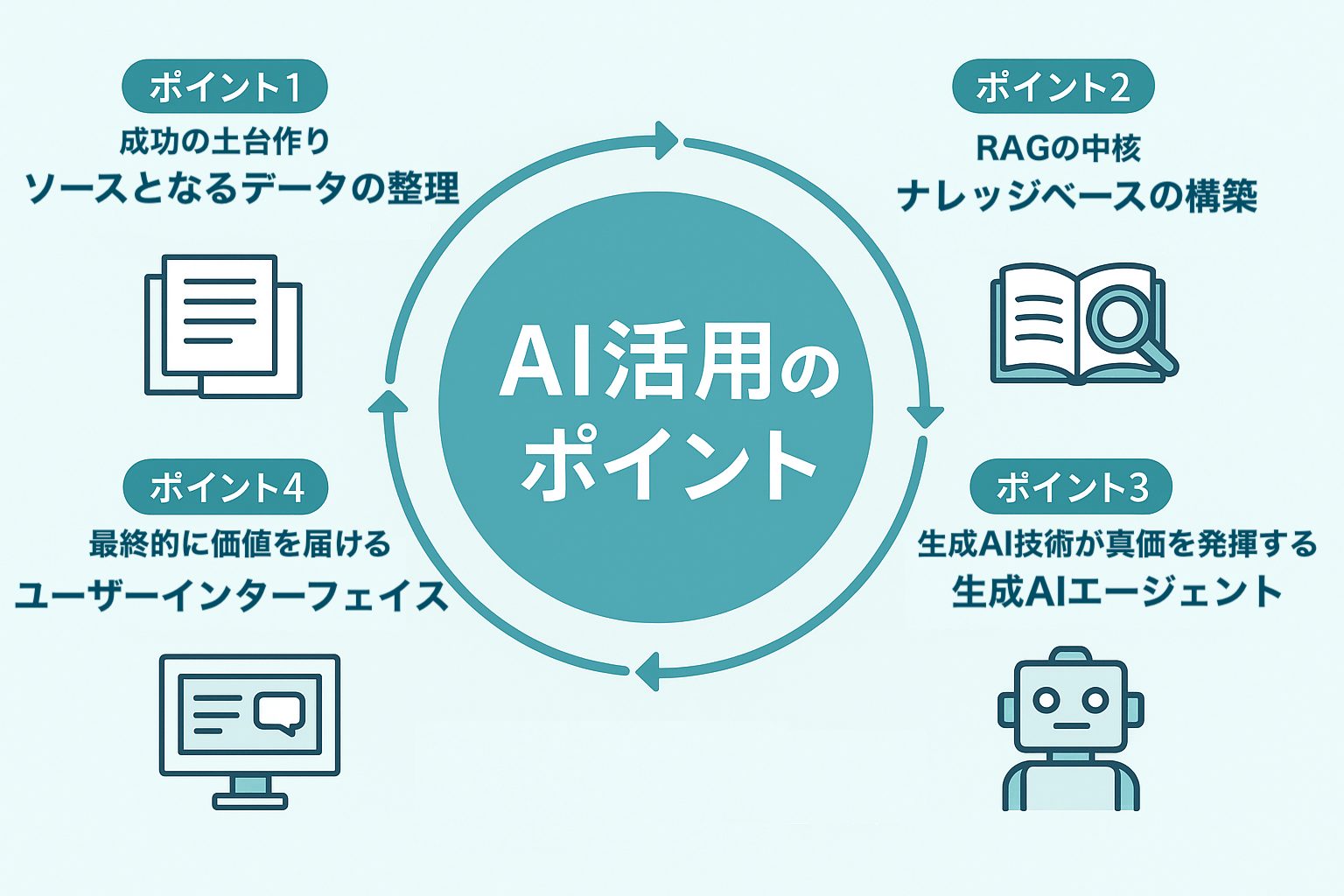
本記事では、社内データを使った生成AIシステムの構築プロジェクトを成功させるために欠かせない4つのポイントと、それぞれの関係性について解説します。
AI活用成功の土台は「データの整理」
ポイントのひとつめは、 成功の土台作りとなる「ソースとなるデータの整理」です。
コンピュータの世界では以前から「Garbage In, Garbage Out(ゴミを入れれば、ゴミしか出てこない)」という言葉があります。これは生成AIでも同じことが言えます。優秀なAIでも、元となる情報が古かったり間違っていたりすれば、正しい答えを引き出すことができません。生成AIが出力する情報の品質は、入力されるソースデータの品質に直結します。
例えば、生成AIに読み込ませる業務データは以下のようなことを考慮する必要があります。
- 情報の鮮度と正確性: 最新の情報が使われているか?誤情報が混在していないか?
- ノイズの除去: 生成AIの理解を妨げる不要な情報は除去できているか?
- 一貫性と整合性: データの形式や定義が統一されているか?異なるデータ間で矛盾はないか?
- 網羅性: 必要な情報が欠落していないか?特定の情報に偏りがないか?
- 粒度: 生成AIが目的とするタスクに必要な詳細度でデータが提供されているか?
- 構造化: 生成AIが情報を効率的に処理できるよう、データが整理された形式(例:タグ付け、カテゴリ分け)になっているか?
業務データを整理する作業は地味に思えるかもしれません。しかし、これは生成AIが信頼できる回答を出すための、非常に重要な土台となります。
「会社のストレージ内にあるデータが散らかりすぎていて、とても整理なんてできない」と考えている人もいるでしょう。ですが、最近ではこのデータ整理自体も生成AIに手伝ってもらい、効率化できるサービスやツールも登場しています。
AI・機械学習を使ったストレージのデータ整理により、データの自動分類、重複ファイルの排除、不要なファイルの特定などを効率的に行えます。
ただし、AIが100%完璧に処理できるわけではないため、人間が最終確認や調整を行うことが重要です。
- 自動分類: AIがファイルの内容を分析し、企画書や経費精算書などのカテゴリに自動で仕分けを提案します。AIの提案を人間が確認・調整することで、手作業の負担を大幅に減らせます。
- 重複排除: 大量のデータの中から、全く同じか似ているファイルをAIが探し出し、削除候補として提示します。最終的な削除判断は人間が行うため、重要なファイルを誤って削除するリスクを避けられます。
- 非構造化データの整理: PDFや画像といった形式の違うデータを解析し、自動でタグ付けや要約の候補を生成します。これにより検索性が向上し、必要な情報を素早く見つけられるようになります。
ストレージの整理は多くの人にとって共通の悩みですが、「無理だ」と諦めず、まずはできる範囲でデータを整えることが、生成AIをうまく活用するための第一歩です。
AIの応答品質を決定づけるナレッジベース
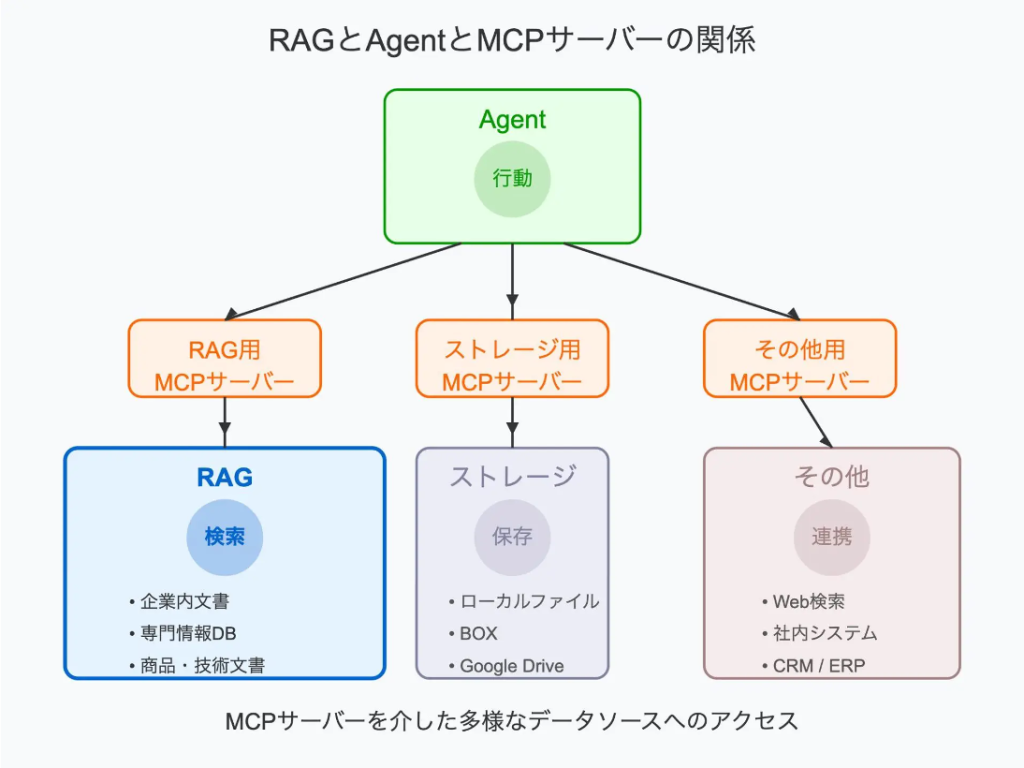
ポイントの2つめは2、RAGの中核を作る「ナレッジベースの構築」です。特にコアとなる業務データに関しては、「ナレッジベース」を構築することで、より高速かつ正確にデータを引き出すことができます。これはいわゆる「RAG(検索拡張生成)」という技術の心臓部です。
RAGを分かりやすく例えるなら、生成AIに「業務データの専門書を与えて、開いたページを見て答えさせる」ようなものです。これにより、生成AIにもともと持っていない専門知識や最新情報を与えることができ、さらに根拠に基づいた正確な回答を生成できるようになります。
関連記事: RAGについて詳しく知りたい方は「生成AIと独自データを組み合わせたサービスの作り方」も併せてご覧ください
この「ナレッジベース」の質が低いと、生成AIは見当違いのページを開いてしまい、ユーザーの質問に的確に答えられません。精度を高める代表的な技術要素が2つあります。
- チャンキング(分割):長いドキュメントを「章」「節」「意味のある段落」といった適切な塊に分割します。例えば「A製品の返品規定」といった具体的なトピックごとにテキストを区切ることで、生成AIは関連情報をピンポイントで見つけやすくなります。
- エンベディング(ベクトル化):各テキストの塊が持つ「意味」や「文脈」を数値(ベクトル)に変換します。例えば「費用を返還する」と「払い戻す」は単語は違いますが、意味は近いです。このような言葉は、ベクトル空間上で近い場所に配置されます。これにより、ユーザーが多少違う言葉で質問しても、生成AIは意味の近い情報を柔軟に見つけ出すことができます。
この工程での精度向上は、生成AIの応答品質を決定づける重要な鍵となります。
ただし、このナレッジベースには重要な注意点があります。ナレッジベースのチューニングは、ドキュメントの特性に合わせた専門的なチューニング領域ですので、高い精度を出すにはコストと時間がかかります。また、多くのナレッジベース用のデータベースは、運用費用が高価なものになります。全てを完璧にすることにこだわるのではなく、重要な業務データに焦点をあてて、コストパフォーマンスやタイムパフォーマンスが良い開発をすることが重要です。
自律的に思考し、行動するAIエージェント
ポイントの3つめは、生成AI技術が真価を発揮する「AIエージェント」の活用です。ナレッジベースから関連情報を取り出した後、最終的な回答を生成するのが生成AIエージェントの役割です。
AIエージェントとは、LLM(大規模言語モデル)を核として、自律的に思考し、行動を実行できるAIのことです。ユーザーの指示を受けて、単にテキストを生成するだけでなく、外部ツールを使ったり、インターネットで情報を検索したり、複数のステップを計画・実行したりして、複雑なタスクを完了させることができます。
ここで、ChatGPTやClaude、GeminiといったLLM(大規模言語モデル)が力を発揮し、生成AI技術の真価が問われます。
単に情報を取得するだけでは不十分で、生成AIエージェントに「どう考えさせ、どう答えさせるか」を的確に指示することが重要です。また、採用するモデル(ChatGPT、Claude、Gemini等)の特徴や能力が、システム全体の回答品質に直接影響するため、適切なモデル選択も欠かせません。
また、モデル選択以外でも精度向上のための手法はいくつかあります。ここでは代表的な2つを紹介します。
- プロンプトエンジニアリング: 生成AIエージェントへの指示文(プロンプト)を工夫し、より的確な回答を生成するように誘導します。例えば、「段階的に考えて回答せよ」「専門用語は分かりやすく説明せよ」といった指示により、回答の質を大きく改善できます。
- 出典の明記: 回答の根拠となった情報源を明示させ、ユーザーが事実確認できるようにします。これにより業務利用においても信頼性を担保することができ、生成AIエージェントの回答に対する信頼度を高める効果があります。
「業務データ×生成AI」というプロジェクトにおいてこれらの調整を行うことは、業務のドメイン知識と生成AI技術の両方の理解が求められる専門的なチューニング作業です。そのため難易度が高い作業になりますが、適切に実装することで、生成AIエージェントは単なる検索ツールから、信頼できる「知的パートナー」へと進化します。
真に使えるシステムにするにはUIも重要
最後のポイントは、ユーザーが実際に使うインターフェース(UI)です。
優れたAIとは、単に性能が高いだけでなく、ユーザーが使いやすいインターフェース(UI)を備え、具体的な業務課題を解決できるものです。どんなに高性能なAIでも、使いにくければその真価を発揮できません。優れたUIはAIの力を最大限に引き出し、ユーザーの業務に自然と溶け込ませるための重要な要素です。
AIを導入する際は「誰が、どのような業務で、何を実現したいのか」を深く理解し、目的に応じて最適なUIを用意することが大切です。
よくあるAIの活用目的
「業務データ×生成AI」で業務効率化を図る場合、次のような使い方はよくあるのではないでしょうか
- 文書生成支援:報告書やメールのドラフト作成など、特定のドキュメント作成を支援する場合に有効です。クリエイティブな作業の効率化に貢献します。
- 情報要約:膨大な資料の調査や、その内容の要約といった業務に向いています。効率的な情報収集が求められる専門業務で威力を発揮します。
「AIで業務効率化を図る」というような大きなテーマ設定だけではなく、このように「何を実現したいのか」まで考慮することで、目的に応じたUIを検討できます。
対話型UIの2つの導入パターン
ChatGPTに代表されるように多くの生成AIは対話型(チャット形式)のUIを採用しています。
対話型UIを採用するとしても、その実現方法はひとつではありません。たとえば下記の2つの選択肢があり、どちらが業務への導入に適しているかを考えることは大切です。
- 独立したチャットUIを用意する:AI専用のチャット画面で利用する形式です。高いカスタマイズ性により、特定の業務に最適化されたインターフェースを構築できます。
- 既存チャットのUIを利用する:SlackやTeamsといった既存のチャットツールにAIを組み込む形式です。ユーザーが慣れ親しんだ環境で利用できるため、導入障壁を大幅に下げられます。
同じAI技術を使っても、UIの良し悪しや、それが解決する業務内容との組み合わせ方で、ユーザーの生産性は大きく変わります。技術的な精度と同じくらい、UIへの投資とユーザーの業務理解がプロジェクトの成功を左右する鍵となります。
4つのポイントは「連携」して初めて価値を生む
ここまで4つのポイントを解説してきましたが、これらは決して独立したものではありません。一つの鎖のように密接に連携しており、これらのバランスが悪いと全体の品質が大きく低下してしまいます。
例えば、完璧なソースデータがあっても、ナレッジベースの検索精度が低ければ宝の持ち腐れです。また、優れたAIエージェントも使いにくいUIではユーザーに価値を届けられません。
私たちNCDCは、独自の業務データを効率的に活用できる企業向け生成AIアシスタント「BizAIgent」を開発しました。BizAIgentは、MCP(Model Context Protocol)という最新の技術でさまざまな業務データと連携し、これら4つのポイントを包括的に解決します。
関連記事: AIエージェントやMCPについて詳しく知りたい方は「生成AIの進化:RAGからAIエージェント、そしてMCPやA2Aの時代へ」も併せてご覧ください。
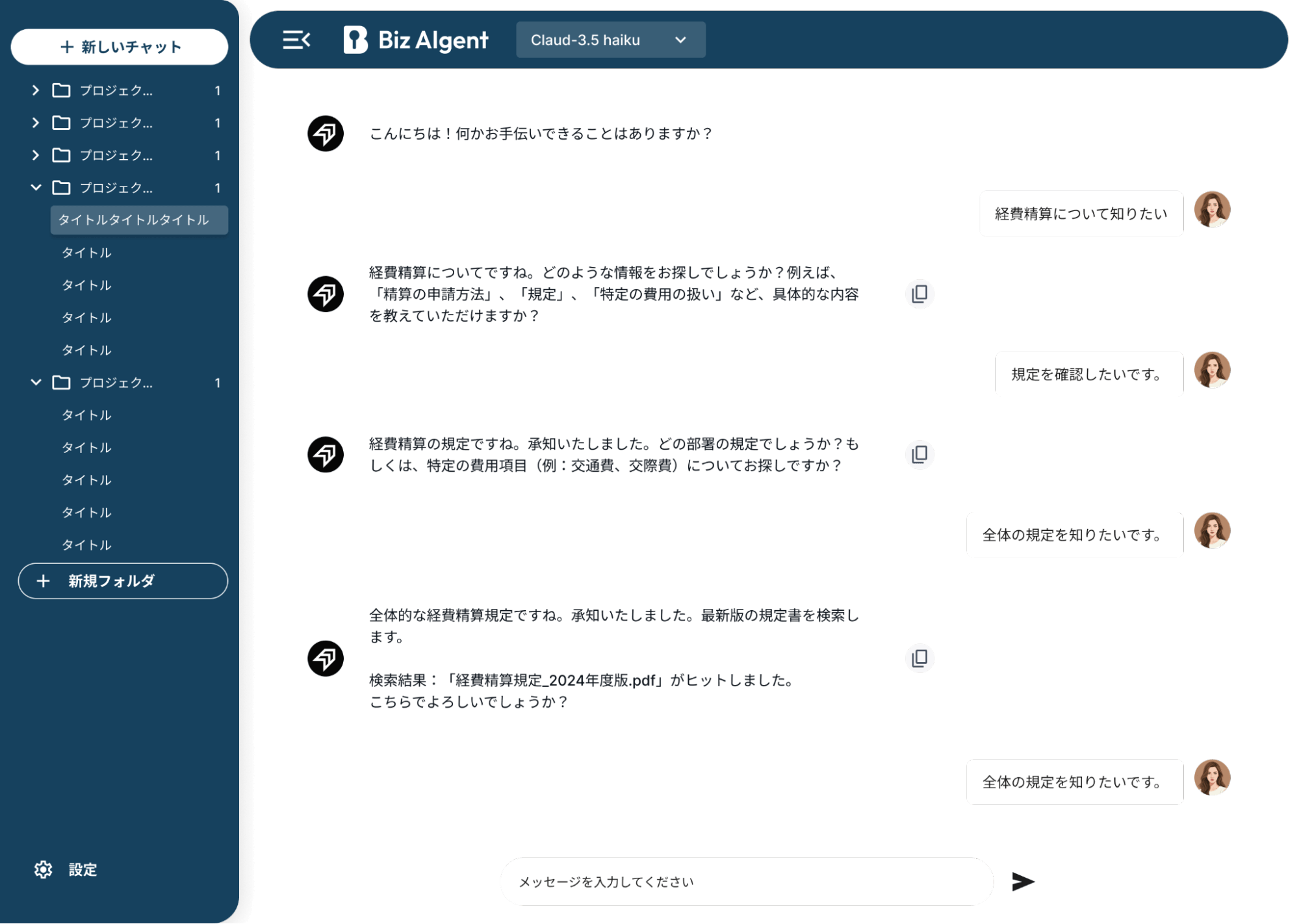
企業向けサービス「BizAIgent」のご紹介
BizAIgentを使用することで、企業が使用しているSaaSや社内システムの情報を使用して、セキュアに生成AIを利用することができます。
「業務データ×生成AI」で業務効率化を成功させる際に、もっとも気にされるのは情報セキュリティですが、BizAIgentは「自社の環境内で運用」できるAIであるため、安心してご利用いただけます。機密性の高いデータを外部に送ることはないので、安全に生成AIを活用できます。
BizAIgentの特徴
- 生成AIエージェントとチャットUIを併せ持つアプリケーション
- MCPを通じて、様々な業務データを横断的に連携 ※1
- クラウドストレージ ( Google Drive、Box、OneDrive、SharePoint )
- 各種SaaS (Teams、Slack、Backlog、Salesforce、Notion、etc)
- 社内のナレッジベースやRAGシステム
- 社内システム
- etc
- 業務利用を前提としたセキュリティ
- 入力した情報はAIの学習に利用されない
- 独立したセキュアな環境で動作
※1 記載のサービスは連携機能を開発中のものを含みます。また、企業独自のシステムと連携する場合は別途アダプターの開発が必要になります。詳細はNCDCまでお問い合わせください。
本記事でご紹介したように、社内データを活用した生成AIプロジェクトを成功させるには、次の4つのポイントを、一体のシステムとして連携させることが重要です。
- ソースとなるデータの整理
- RAGの中核となるナレッジベースの構築
- 生成AIエージェントのチューニング
- 使いやすいUI
一企業がゼロからこうしたポイントを踏まえたシステムを構築するのは難易度が高いといえます。しかし、BizAIgentを活用すれば、個別の技術要素を組み合わせる複雑さを解消し、手軽に生成AIによる業務効率化を実現できます。
BizAIgentが「業務データ × 生成AI」というかたちで業務効率化の基盤を提供することで、お客様は技術的な課題に煩わされることなく、企業価値の向上という最も重要な仕事に集中していただけるようになります。
生成AI活用の相談はNCDCへ
NCDCは、生成AIを活用した課題解決を包括的にご支援しています。生成AIエージェントとわかりやすいUIを迅速に提供する「BizAIgent」はもちろんのこと、その土台となるデータ整理やナレッジベースの構築においても豊富な構築実績があります。さらに、こうした仕組みをお客様自身が構築・運用できるよう支援する「内製化支援」にも力を入れています。
このようにNCDCでは、データ活用からUI/UXデザイン、システム開発まで、ビジネス価値を最大化する生成AIソリューションの実現をワンストップで支援しています。お客様の状況や目指すゴールに合わせて最適な形でご提案しますので、ぜひお気軽にご相談ください。
“`