目次
2024年5月29日にオンラインセミナー『クラウド活用で生成AIを業務に取り入れる方法』を開催いたしました。
この記事では当日用いた資料を公開し、そのポイントを解説しています。。
生成AIの種類
ひとことで生成AIと言っても実はさまざまな種類があります。
下のリストのとおり言語モデル、画像生成モデル、動画生成モデル、グラフ生成モデルなどの種類があり、その中に多様なモデルが存在しています。
主な生成AIの種類
- 言語モデル(GPT、Gemini、Claude、など)
- 画像生成モデル(DALL-E、 Midjourney、など)
- 動画生成モデル
- グラフ生成モデル
本セミナーのテーマはこの内、生成AIの「言語モデル」です。
実は上記の「主な生成AIの種類」も生成AI(Claude3 Opus)をつかって作成したリストを載せています。こうしたセミナー用の資料作成などには生成AIがかなり使えるのではないでしょうか。
生成AIをユースケースで分類
生成AIをユースケースで分類すると次の2つに分けられます。
- パブリックな生成AIの利用
- プライベートな環境での生成AIの利用
「パブリックな生成AIの利用」とは、サービスとして広く世間に提供されているAIを利用するケースです。例えばWEBブラウザでChatGPTのサイトにアクセスして、ChatGPTに「主な生成AIの種類を教えて」と質問するような使い方が考えられます。
もう一つは「プライベートな環境で生成AIを活用する」ケースです。例えば、自社で契約しているAWS上に自社用の生成AIを用意して使うのがこれにあたります。(Google cloud、Azureなどでも可能です)
この後は「パブリックな生成AI」と「プライベートな環境の生成AI」の2分類について、それぞれのメリット・デメリット、導入の注意点、具体的な活用例などを紹介していきます。
パブリックな生成AIの活用について
パブリックな生成AIとは、先述の通りWebブラウザでChatGPTやGemini(Google)を使うケースを指しています。
Googleの生成AIサービスとしては、自分のGmailの受信トレイから情報を探して、要約し、整理してくれるというものも提供されています。そうしたサービスを使うのもパブリックな生成AIの利用にあたります。
よく使われるパブリックな生成AIサービス
- ChatGPT(OpenAI)
- Gemini(Google)
- Claude(Anthropic)
ChatGPTやGeminiの他によく使われるものとしてはClaudeというサービスがあり、これは精度が高いと言われています。
Webブラウザから使えるサービスなので使い勝手がよく、次に説明するデメリットに注意して使用すれば十分に業務利用の候補になります。
パブリックな生成AIのメリット・デメリット
メリット
パブリックな生成AIは、ブラウザで開けばすぐに使える。サービスによって違いはあるが多くは無料でも一部機能が使える。課金しても月に数千円程度と安価で使える等のメリットがあります。パブリックなサービスはサービス提供者が随時アップデートしてくれるので、ユーザーは何もしなくてもどんどん便利に進化していくこともメリットです。
ChatGPTでもGeminiでもはじめから幅広い分野の学習がされているので、一般論であれば大抵のことは回答が得られるものメリットです。
デメリット
パブリックな環境にある生成AIにはデメリットもあります。もっとも注意すべきなのは、入力したデータがそのサービスの「学習」に利用されてしまうことです。規約をしっかり読んで個々に判断が必要ですが、基本的には入力したデータは保護されないと考えておく方が無難です。
ユーザー独自のカスタマイズはできない。プランによっては回数制限などの制約がある。これらもデメリットだといえます。
パブリックな生成AIの業務利用とセキュリティ問題
生成AIを業務に利用するなら入力したデータが保護されないと困る。ほとんどの人がそう考えるでしょうが、先述したようにパブリックな生成AIを利用する限りデータの保護は難しいといえます。
そのため、この問題のもっとも簡単な解決方法は「生成AIの業務利用禁止」です。
ただ、単純に禁止と言われても、Webブラウザさえあれば誰でも簡単に使える生成AIがいくつも存在するので、結局は勝手に社員が使ってしまうリスクがあります。そのため、会社が規定を決めてコントロールできる範囲で社員に利用してもらうのがおすすめです。
(もちろん、しっかり検討した上で「業務利用は全面的に禁止」という結論になれば、それでも良いと思います)
仮に「生成AIはまだ発展途上なので業務には使わない方が良い」と決めた場合でも、現時点で生成AIの業務利用問題にしっかりと向き合い、利用規約や、この範囲内なら利用可能というようなルールをつくっておくことは大切です。
生成AI利用について企業が決めるべきこと
では、具体的に社内の生成AI利用ルールには何を盛り込むと良いのでしょうか?
この問題自体をAIに聞いてみるのもひとつの手です。
生成AI(GPT-4)に出してもらったルールの項目案が下記のものです。
- どの生成AIサービスを使ってもよいか
- 各サービスの利用規約を読むこと
- 業務情報(特に個人情報)を入力しないこと
- 著作権の問題はないかを確認する
- 結果に誤りがないかの確認をする
まず、どの生成AIサービスを使って良いのか?という決め事があります。先に主要な生成AIサービスを挙げましたが、それ以外にも多くのサービスが出ているので、どれを利用可とするのかは決めておく方が良いでしょう。
次に、当然のことですが、きちんと利用規約を読んで理解してから使うこと。その他にも、業務情報、特に個人情報は絶対入力しない。著作権の問題がないかを確認して利用する等の決め事が大切です。
また、生成AIが誤った結果を返すことはよくあるので、参考情報として生成AIを使いつつも、人間がその情報の裏を取るというのは生成AIを業務利用する上で欠かせないルールです。
自社の生成AI利用ガイドラインを公開している会社もあるので、それを参考にするのもひとつの方法です。Google等の検索エンジンで「生成AI 利用 ガイドライン」と検索するとすぐ見つかります。
生成AIによる「生成AI利用ガイドライン」
生成AIに社員向けガイドラインの雛形を用意してもらうこともできます。
生成AI(Gemini 1.5 pro)に出してもらったガイドラインの案をこのページの末尾に載せています。出力されたものをそのまま貼っており内容の検証はしていないので、参考にする方は自分で内容をしっかりチェックしてから使うようお願いします。
パブリックな生成AIの業務活用例
続いては、ガイドラインを作ったうえで、生成AIをどう業務に活かすかという話です。
業務上の重要情報は生成AIに学習されてしまうと困るので入力を避けるとして、他にどのような活用方法があるのか、いくつか例を挙げておきます。
- 情報収集・整理
- 文献レビュー: 論文やレポートの要約・重要ポイント抽出
- 市場調査: Web上の情報収集、市場トレンド・競合分析
- 文章作成・編集
- プレゼン資料作成: スライド構成・内容提案、作成効率化
- 校正・推敲: 誤字脱字指摘、表現改善、文章の質向上
- アイデア出し・企画立案
- ブレインストーミング: 新商品・サービスのアイデア出し
- マーケティング企画: ターゲット層・プロモーション戦略立案
- コンテンツ企画: ブログ記事・SNS投稿のテーマ・構成提案
- その他
- プログラミング: コード生成、デバッグ、ドキュメント作成
- カスタマーサポート: FAQ作成、チャットボット、多言語対応
- 翻訳、データ分析、教育・研修支援など
パブリックに出ている論文・レポートなどを全部読むのは大変なので、AIに資料を渡して要約してもらう、重要なポイントだけ抽出してもらうという使い方が考えられます。
市場調査の一部として、市場トレンドなどの情報をAIに集めて要約してもらうのも可能です。
文章を作りたい時に、ポイントだけを伝えて文章を書く作業は生成AIに任せたり、つくった文章の推敲をAIに任せたりすることもできます。
生成AIに資料の構成を考えてもらう、内容を提案してもらうこともできます。実際に、上記の「パブリックな生成AIの業務活用例」のリストは生成AI(Gemini 1.5 pro)に用意してもらった案を別の生成AI(Claude3)でまとめたテキストを使用しています。
新商品のアイデアをAIとチャットしながら集めていくというのもできますし、マーケティング企画でターゲット層の検討やプロモーション戦略の立案をAIと相談しながら考えることもできます。
ブログやSNSに投稿するコンテンツを考えてもらうこともできます。
生成AIはコーディングにも使えます。AIに「こういうコードを書いて」と指示すればコードを返してくれますし、反対に生成AIにコードを貼ってドキュメントを作ってもらうこともできます。
その他には、カスタマーサポートの分野で、過去の質問と回答のデータからFAQを作ってもらう。チャットボットの対応してもらう。
生成AIに翻訳してもらうという利用法も考えられます。
業務上の重要情報は生成AIに渡さないという制約があるとしても、このようにパブリックな生成AIを使える分野は意外と多いのではないでしょうか。
プライベートな生成AIとクラウドの活用
ここまでパブリックな生成AIの業務利用について説明してきましたが、ここから先は最初に分類したもうひとつのユースケース「プライベートな環境での生成AI」について説明していきます。
プライベートな生成AIの中でも大きく二つの分類があります。
- 「事前学習済みモデルを利用」するケース
- 「生成AIモデルを自分で作成」するケース
まず後者の「生成AIモデルを自分で作成」について説明します。例えばAWSでは、機械学習を実施するうえで必要なモデル開発、学習、推論などの機能を提供するAmazon SageMakerというサービスを提供しています。こうしたクラウドサービスを活用することで、自分で機械学習のAIモデルを作ることが可能です。
機械学習とは簡単にいうと与えられたデータからコンピューターが自動で学習を進め予測などを行うAIで、生成AIを構成する要素の一つです。そのため、機械学習モデルを自分で作成できれば、自社のニーズに合わせて最適化した生成AIを構築可能です。
しかし、機械学習の自作からはじめる生成AIモデル開発は、導入のハードルが非常に高いといえます。また、導入後も自分でメンテナンスし続けていく運用コストがかかります。
生成AIモデルを自作するのは容易なことではありません。
一方で、前者の「事前学習済みのモデルを利用」は、AWSやGoogle Cloud、Azureなどのクラウド上に用意したプライベートな環境(隔離された自社だけの環境)の上に既存の学習済みモデルを設置して使用するという方法です。
「生成AIモデルを自分で作成」することの難易度と比較すると「事前学習済みモデルをクラウド上で使う」のは容易に導入できて、スケーラビリティも高く、費用も比較的抑えられます。そして、パブリックな生成AIを利用するよりセキュリティは高いので、「いいとこ取り」ともいえる手法です。
主要なクラウド上でよく使われる生成AIモデル
では「事前学習済みのモデルを利用」する場合、具体的にはどのような生成AIモデルが使えるのか? 主要なクラウド(AWS、Google Cloud、Azure)上で使えるものをいくつかを紹介します。
主要なクラウド上でよく使われる生成AIモデル
- GPT-4:Azure ( Azure AI services )
- Gemini 1.5 Pro:Google Cloud ( Vertex AI )
- Claude 3 Opus、 Claude 3 Sonnet、 Claude 3 Haiku:AWS ( Amazon Bedrock )、Google Cloud ( Vertex AI )
もっとも有名なGPTはAzureで使えます。当然ですが、Googleが開発したGeminiはGoogle Cloudで使うことができます。先にも名前挙げたClaudeはAWS(Amazon Bedrock)で使うことができます。
あまり知られていないようですが、Claude はGoogle Cloudでも使うことができます。GoogleはGeminiもClaudeも使えるのが特長です。
お気づきかと思いますが、これらは先述した「パブリックな生成AI」と同じモデルです。簡単にいうと、パブリックな生成AIと同じものを自社で利用しているクラウド上の閉じられた空間内で使えるのです。
生成AIモデルの選び方
このようにさまざまな生成AIモデルの選択肢があり自由に選ぶことができますが、生成AIを業務利用する場合の利用シーンを考えると、自社で使っている他のアプリやクラウドサービスとの連携が必要になることも多いのではないでしょうか。
そのため、新たに生成AIモデルを選定する際は知名度が高いというような理由だけで決めるのではなく、既存アプリとの連携のしやすさなども考慮して総合的に判断して選ぶのがおすすめです。
事前学習済みモデルを使うメリット・デメリット
メリット
プライベートな環境で事前学習済みの生成AIモデルを利用する場合は、導入が容易で、セキュリティとプライバシーが確保できる。はじめから学習済みで性能が高いAIを利用できる上に、サービス提供者が継続的に改良・更新してくれる。利用した分だけの課金になるのでコストの効率が良い。
これらがメリットとして挙げられます。
デメリット
デメリットとしては、AIモデルのカスタマイズができないため、一般的な問題の回答は得られますが「自社だけが保有する業務データを反映した回答」のようなものは得られないことが挙げられます。
また、サービスの停止や変更の影響を受けるリスクも考える必要があります(ただし、この点は大手のクラウドを使っていれば自社の業務に影響が出るようなリスクは小さいといえます)。
先にコスト効率が良いというメリットを紹介しましたが、クラウドは利用量に応じた重量課金なので費用の予測が困難な点はデメリットともいえます。利用量が事前に予想しづらく、想定外の利用料がかかる可能性もあるので、企業としては予算超過のリスクがあって使いづらいという問題は起こり得ます。
これらのデメリットの中で、業務利用においては「自社専用のカスタマイズができない」ことが一番大きな問題ではないでしょうか。
実は、AIモデルのカスタマイズまでしなくても、自社独自のデータをAIと組み合わせて利用することは可能です。よく使われるRAG(Retrieval-Augmented Generation)と呼ばれる手法があるので、続いてRAGを解説します。
クラウドを活用したRAGの構築
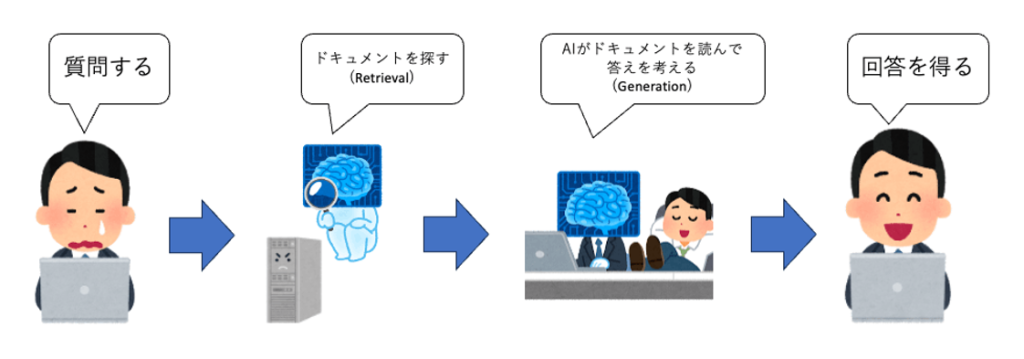
RAGは検索拡張生成とも言われているもので、検索と拡張生成の2ステップで構成されるようなアプリケーションです。
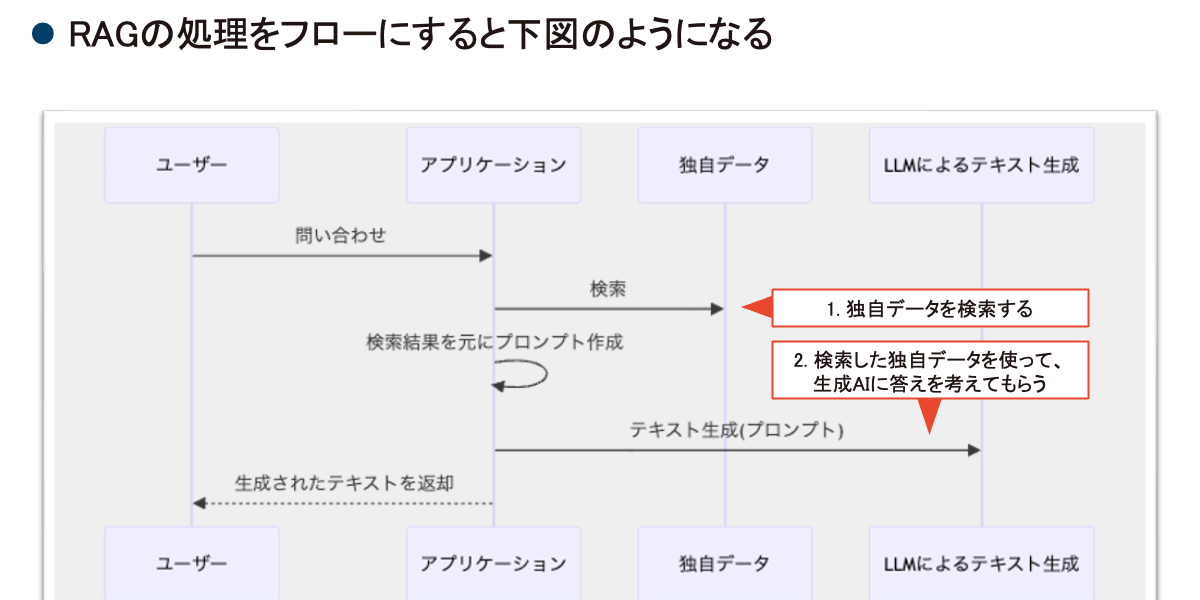
下図のように「ユーザーからの質問」を受けると、まずRetrieval(検索)が行われます。独自のデータを事前にクラウドやファイルサーバーに置いておき、そこに対して検索をかけて目的のドキュメントを探してくるのです。
次に、検索で見つけたドキュメントと、もとの「ユーザーからの質問」をセットでAIに渡すと、AIがドキュメントを読んで、その内容から回答をAugmented Generation(拡張生成)するという処理が行われます。
この組み合わせがRAGと呼ばれています。
はじめに「学習済みの生成AIモデル」がもともと持っていない情報を指定したデータ内から検索するというステップを挟むことで、生成AIモデルの性能に独自の情報を組み合わせて回答が得られるという仕組みです。
下図はRAGの処理フローです。繰り返しの説明にはなりますが、ユーザーが問い合わせをしたらアプリケーションが動き、アプリケーション内で独自のデータを検索しに行きます。その検索結果をもとにAI用のプロンプト(AIに問い合わせるための文章)を作り、最終的にAIにより生成された回答をユーザーに返すという処理をしています。
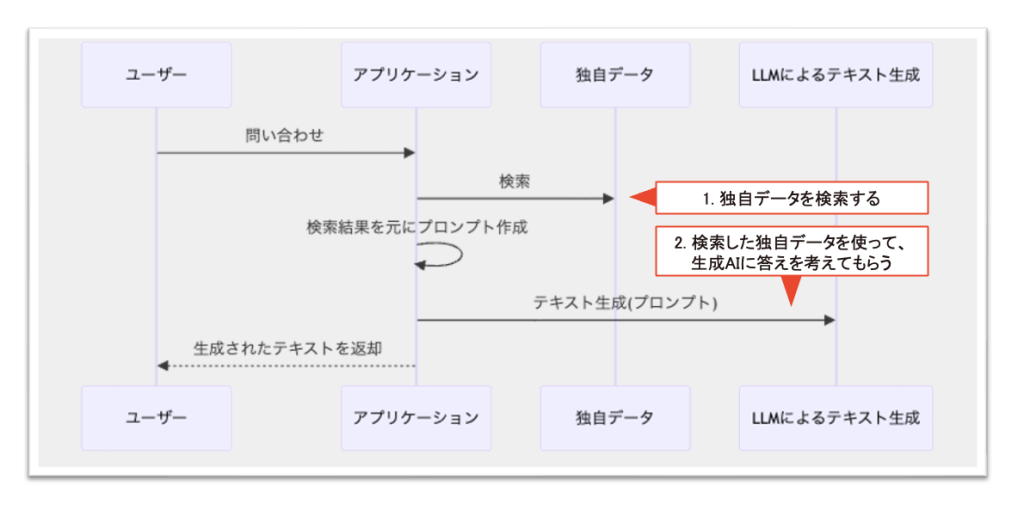
さらに具体的なRAGの例として、Slackなどのチャットと連携するRAGをAWSで実現する構成を一例として載せておきます。
- 事前に「独自データ」として生成AIに利用させたい各種ドキュメントをAmazon Simple Storage Service (Amazon S3) というストレージに置いておきます
- Amazon Kendraという全文検索のサービスを利用してストレージ内のデータを検索します
- 検索結果をAWS Lambda内のアプリケーションで処理して、Amazon Bedrockという生成AIのサービスにプロンプトを渡します
- その結果をユーザーに回答します

RAGを構築できるクラウドサービスの例
上図ではAWSの構成例を用いて説明しましたが、AzureやGoogle Cloudにも検索や生成AIの機能を提供するサービスはあるので、同等のサービス使うことでAzureやGoogle CloudでもRAGを構築できます。
複数のクラウド組み合わせる構成も可能です。アプリ側で検索のデータを取得する部分はAWSで行い、生成AIの部分はAzureに連携して処理するという構成も十分に考えられます。
生成AI導入の検証時に、アプリ自体はAWS上に一つだけ用意して、AIの部分をAWSとAzure、Google Cloudそれぞれに連携させて、どのAIモデルが期待に近い回答を返してくれるか検証するというようなRAGの作り方も考えられます。
業務におけるRAGの利用例
業務におけるRAGの利用例として、NCDCの就業規則を学習させたSlackと連携するアプリの画面を掲載しておきます。
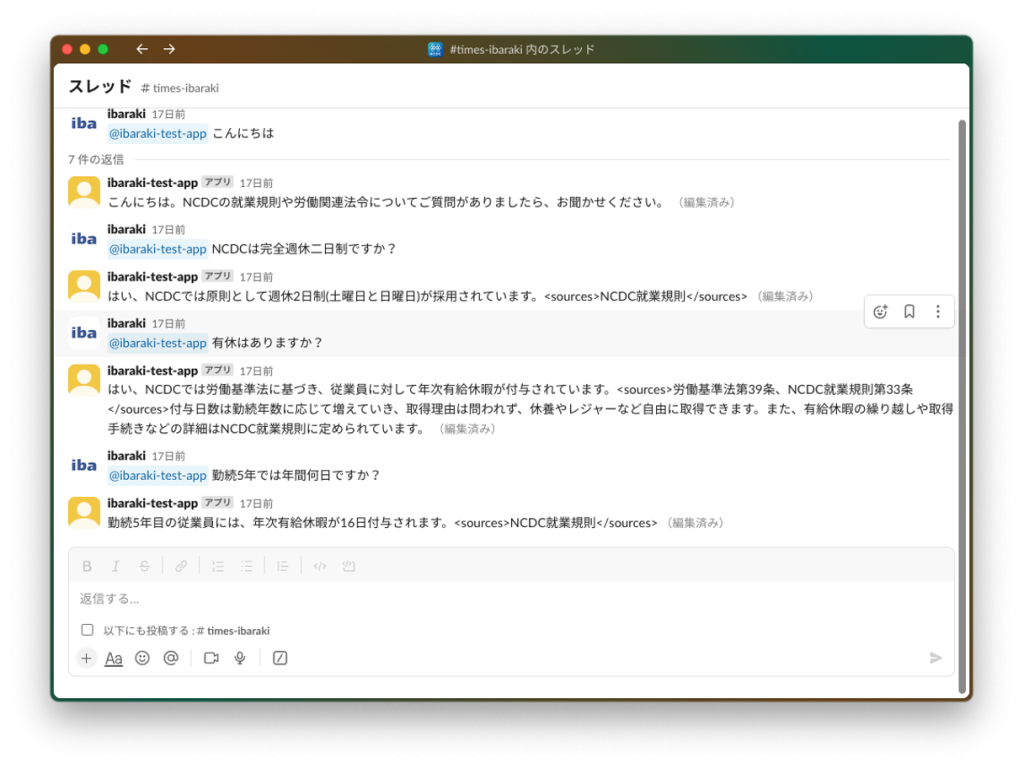
「有給はありますか?」という質問に対して、「労働基準法に基づいて年次有給休暇が付与される」ことや「勤続年数に応じて増えていく」を答えてくれています。
また、生成AIは対話の文脈を理解して回答してくれるので、次に「勤続5年では年間何日ですか?」という、この一文だけでは何に対する質問か意味がわかならない言葉を書いても、きちんと「勤続5年目の有給休暇の日数」について回答してくれます。
このくらいのRAGであれば、作り方を理解していれば比較的容易に構築可能です。
RAG構築時に注意すべきこと
AWS等の提供するサービスを使えば、RAGは比較的簡単に構築できると説明してきましたが、単純に動けばいいのではなく、業務で役立つレベルにするには注意点もあります。
RAG構築の注意点1:検索のコスト
ひとつめの注意点はコストです。
RAGの回答精度をよくするには、独自データの検索部分をしっかりつくっておく必要があります。
ただ、検索部分のサービスとして先に紹介したAmazon Kendraは利用料が高めです。重量課金制ではありますが一か月間ずっと立ち上げておくと最低でも今の為替で月額12万円ぐらいかかります。夜間は落としておくなどの節約方法は考えられますが、常時起動だと月額10万円以上になるという目安にしてください。もちろん重量課金なのでRAGの利用量が増えるともっと多くのコストがかかります。
今は円安なので、AWSなどの海外サービスを日本で利用する場合は為替変動でより高くなる可能性も考慮しておく必要があります。
先日、ほとんど使われてないテスト環境のRAGアプリに実際かかったインフラコスト(1週間分)を調べたところ、下記のようになっていました。
- 検索用のAmazon Kendraが約30,000円
- 生成AIのAmazon Bedrockは約100円
- アプリ本体は3円程度
この結果から年間コストを単純試算すると150万円ぐらいになってしまうので、検索部分のインフラ(Amazon Kendra)に多くのコストがかかるのがよくわかると思います。
Amazon Kendraの代わりにオープンソースの検索サービスを使えば運用費は抑えられますが、その代わりにチューニングが必要になり構築の費用が嵩んだり、精度が悪かったりする恐れがあります。
またAWS以外のクラウドを使う場合も検索部分の費用はどれも安いとはいえません。
そのため、RAGの導入を検討する場合は、月に数十万円のコストが発生するとしても導入する価値があるのか?という検証も必要です。
RAG構築の注意点2:精度以外への配慮
二つめの注意点は、回答精度が高ければ必ず業務に役立つとは限らないことです。
RAGに限らずどのアプリケーションも同じですが、精度の高い回答を返せる(技術的に優れた)ものが出来てもユーザーにとって使いにくいと誰も使ってくれません。生成AIは現時点では業務に必須なものではなく、少し業務を効率化してくれる便利ツール程度の位置付けではないでしょうか。そのようなツールは特に使いやすさにこだわって作らなければ、はじめは興味をもって使っていたユーザーでもすぐに離れていってしまいます。
RAGの導入を検討する際は、単純に精度だけを求めるのではなく、ユースケースの設計やUIも重要だと認識しておく必要がありす。
RAG構築の注意点3:チューニングの必要性
三つめの注意点は、実業務で使えるレベルを目指すとかなり細かいチューニングが必要になることです。いわゆる「プロンプトエンジニアリング」です。
具体的には下図の吹き出しに書いてあるとおりです。

検索時にはよりユーザーの検索意図に沿った結果を得られるように、ユーザーが入れた質問から検索ワードをカスタマイズする必要があります。ユーザー(人間)は適当なことを書きがちで、機械が検索意図を理解しやすいようにと考えて検索を行ってはくれないので、この工夫は欠かせません。
次に、得られた検索結果からAIが答えやすい質問文を作るところもカスタマイズが要ります。もちろん最終的にAIが返す回答も読みにくければ使われなくなってしまうので、ユーザーが読みやすいようカスタマイズすることが必要です。
こうした質問文や検索文を「いい感じに調整する」作業が、精度向上のためのチューニングとして必要になります。つくって終わりではなく、使いながら細かいチューニングをしていくことの大切さを認識しておく必要がありす。
RAGアプリの今後「生成AIエージェントの活用」
RAGアプリの今後の進化に関して「生成AIエージェント」というものを紹介します。
これまでのGPTなどのチャットは入力に対して単純に回答するという動きをするものでした。そのため、前述のようにRAGを構築する際は検索文を「いい感じにする」ようなチューニングを人が行う必要がありました。
一方で、生成AIエージェントは与えられたタスクを理解して、自分の判断で行動する自律的に動作するアプリケーションです。細かいチューニング(プロンプトエンジニアリング)自体をエージェントに任せることができる。つまり、AI用のプロンプト(AIに問い合わせるための文章)を作ること自体もAIが「いい感じ」にしてくれるので、従来よりもRAGの構築が容易になったり、精度の向上が期待できたりするのです。
例えばAWSのAgents for Amazon Bedrockというサービスを利用することで、比較的簡単に精度の高いRAGを作れるようになりつつあります。
生成AIエージェントの分野は世に出たばかりでまだまだ発展途上ですが、頻繁に新しいサービスが登場してくるので、こうした情報をキャッチしてうまく利用していくことも大切です。
生成AI活用の注意点「海外リージョン」
クラウドサービスはデータセンター(サーバー)が置かれた場所を示す「リージョン」という概念があり、国内リージョンと海外リージョンに大別できます。
生成AIに限らずクラウド全般の話でもあるのですが、利用するものが国内リージョンか海外リージョンかは要確認です。データを海外に置くのは「輸出」にあたるので、海外リージョンの扱いには注意が必要になります。
特に生成AIに関しては最新モデルがアメリカでリリースされるため、最新機能を使おうとするとどうしても海外リージョンを使うことになり、要注意です。
生成AI(GPT-4o)に「最新モデルがリリースされる海外リージョンのサービスを利用する際に注意すべき法律」について質問した結果が下記のリストです。
- 外為法
- 日本の国家機密や軍事用途に転用可能な技術情報
- 経済産業省の規制リスト(キャッチオール規制)に該当する技術やデータ
- 機密情報
- 個人情報保護法 / APPI(個人情報)
- HIPAA(医療データ)
- GLBA(金融データ)
法律については、例えば外為法や個人情報保護法に注意が必要なようです。医療データ、金融データなどはかなり扱いに気をつけないといけないこともわかります。業務で海外リージョンのサービスを使う場合は、法律の専門家や輸出関係の専門家への確認は必要だといえます。また、少しでも不安がある場合は日本国内のリージョンで提供されるサービスを使うのが無難でしょう。
国内リージョンで使える主要モデルで、比較的新しいものとしてはGoogleのGemini 1.5 Proがあります。AzureではGPT-4が使えます。一方、AWSは最新のClaude3は現時点では国内リージョンで使うことができず、一世代古いClaude2なら使えます。
Googleは常に新しいモデルを日本で使えるようにしてくれているので、日本国内のリージョン利用を前提として最新モデルを使いたい場合は、Google Cloudがおすすめだといえます。
ただし、毎回新旧のAIモデルに大きな違いが出るとも限らないので、何を優先するのかは自社の目的に応じて決める必要があります。
まとめ
最後のまとめもAIに作ってもらいました。
Google Cloud上の生成AI(Gemini 1.5 Pro)を使って講演資料を要約したのが下記のテキストです。
- 生成AIをユースケースで分類すると「パブリックな生成AIサービスの利用」と「プライベートな生成AIの活用」に分けられる。
- パブリックな生成AIは手軽に利用できるが、入力データをAIプロバイダーに利用される可能性がある。
- 生成AIを積極的に活用しない場合でも、会社を守るために生成AIの利用規約を定めたほうがよい。
- プライベートな生成AIの活用方法方法として、クラウドを活用したRAG(Retrieval Augmented Generation)が挙げられる。
- RAGとは、生成AIを活用して独自のデータを検索し回答を生成する手法。
- RAG構築時の注意点として、検索部分のコストが高いこと、UI/UXの重要性、プロンプトエンジニアリングの必要性がある。
- 今後のRAGアプリは、生成AIエージェントを活用することで、構築が容易になり、精度向上も期待できる。
- 海外リージョンを利用するときは、特にセキュリティの注意が必要。
- 生成AIは、業務効率の向上や新たな価値創造に貢献できる可能性があるが、メリッ トとデメリット、セキュリティリスクを理解した上で活用することが重要。
生成AIのご相談はNCDCへ
AIは精度向上ももちろん重要ですが、どう使うべきか、使いやすいものであるかも考えないと、結局ユーザーに受け入れられずに終わってしまうので、テクノロジー面だけではなくUXも考慮することが大切です。
NCDCでは生成AIをどういう場所に導入するのか計画を考える段階のコンサルティングから、RAGの構築、精度向上の支援、運用まで一元的にサポートできますので、この記事を読んで興味を持っていただいた方は、ぜひご相談ください。
参考資料
1:生成AIについて学べる記事
AWSのWebサイトに「生成AIをセキュアにする」というシリーズのブログがあり、生成AI活用の分類やセキュリティについて詳しく記載されています。興味がある方はぜひ読んでみてください。文量が多く、英語が原文のため日本語の記事はやや読みにくさはありますが、内容はかなり勉強になります。
生成AIをセキュアにする:データ、コンプライアンス、プライバシーに関する考慮点
2:企業用の生成AI利用ガイドライン
生成AI(Gemini 1.5 pro)でつくった企業用の生成AI利用ガイドライン(案)です。内容の検証はしていないので、参考にする方は自分で内容をしっかりチェックしてから使うようお願いします。
【会社名】生成AI利用ガイドライン(案)
目的
本ガイドラインは、当社における生成AI(Generative AI)の利用に関する基本的なルールを定めることにより、生成AIの適切かつ効果的な活用を促進し、業務効率の向上、創造性の促進、およびリスクの低減を図ることを目的とします。
適用範囲
本ガイドラインは、当社役員、社員(正社員、契約社員、派遣社員、パートタイマー、アルバイト等を含む)、およびその他関係者(インターン、業務委託先等)が業務において生成AIを利用する場合に適用されます。
生成AIの定義
本ガイドラインにおける生成AIとは、テキスト、画像、音声、プログラムコード等のデータを生成するAI技術を指します。
基本原則
倫理的利用: 生成AIを利用する際は、法令、社会規範、社内規程等を遵守し、倫理的かつ責任ある行動を取ること。
情報セキュリティ: 生成AIに機密情報、個人情報、顧客情報等を入力しないこと。また、生成AIの出力結果を適切に管理し、情報漏洩のリスクを低減すること。
著作権尊重: 生成AIの出力結果が既存の著作物と類似していないか確認し、著作権侵害とならないよう注意すること。
正確性確認: 生成AIの出力結果は必ずしも正確ではないことを認識し、必要に応じて事実確認や裏付けを取ること。
継続的学習: 生成AIの技術は日々進化しているため、常に最新の情報に注意し、適切な利用方法を学習すること。
利用における注意点
利用目的の明確化: 生成AIを利用する前に、利用目的を明確にし、適切なツールを選択すること。
入力データの選定: 生成AIに入力するデータは、信頼性が高く、偏りのないものを選択すること。
出力結果の評価: 生成AIの出力結果は、客観的な視点で評価し、必要に応じて修正や改善を行うこと。
フィードバック: 生成AIの利用経験や問題点等を共有し、改善に繋げること。
禁止事項
違法行為: 生成AIを利用して、違法行為、差別的発言、誹謗中傷等を行うこと。
不適切な情報生成: 生成AIを利用して、わいせつ物、暴力的な表現、虚偽情報等を生成すること。
無断利用: 生成AIを業務目的以外に利用したり、他者に無断で利用させたりすること。
違反時の対応
本ガイドラインに違反した場合、就業規則等に基づき、懲戒処分等の対象となる場合があります。
ガイドラインの見直し
本ガイドラインは、必要に応じて定期的に見直しを行い、最新の情報に合わせて改訂します。
問い合わせ窓口
本ガイドラインに関する問い合わせは、[問い合わせ窓口部署名]までご連絡ください。
附則
本ガイドラインは、[施行日]から施行します。
免責事項: 本ガイドラインは、生成AI利用に関する一般的な指針を示すものであり、全ての状況に対応するものではありません。利用者は、自身の判断と責任において生成AIを利用するものとします。
参考資料
一般社団法人日本ディープラーニング協会 (JDLA): 生成AIの利用ガイドライン
総務省: AI利活用ガイドブック