目次
2023年6月29日にオンラインセミナー『DXにおけるデータ活用とは?分析の始め方から有効活用までのヒントを解説』を開催いたしました。 この記事では当日用いた資料を公開しています。
DXの定義とデータ活用の重要性
DX(デジタルトランスフォーメーション)とは何を指すのか、世界共通の正確な定義はありませんが、日本においては経済産業省が2018年に発表した「DXレポート」により広まった次の定義が一般的です。
「企業がビジネス環境の激しい変化に対応し、データとデジタル技術を活用して、顧客や社会のニーズを基に、製品やサービス、ビジネスモデルを変革するとともに、業務そのものや、組織、プロセス、企業文化・風土を変革し、競争上の優位性を確立すること」
(デジタルガバナンス・コード2.0(旧 DX推進ガイドライン)より)
このように、経産省によるDXの定義においてもデータの活用が強調されており、最近では多くの企業がデータ活用に取り組んでいます。その一方で、すべての企業が順調にデータ活用を進められているとは限りません。
データ活用を進めていく中でよく問題となるいくつかの壁があるので、本セミナーでは代表的な壁と、その壁の乗り越え方をご紹介します。
データ活用の基本的な流れ
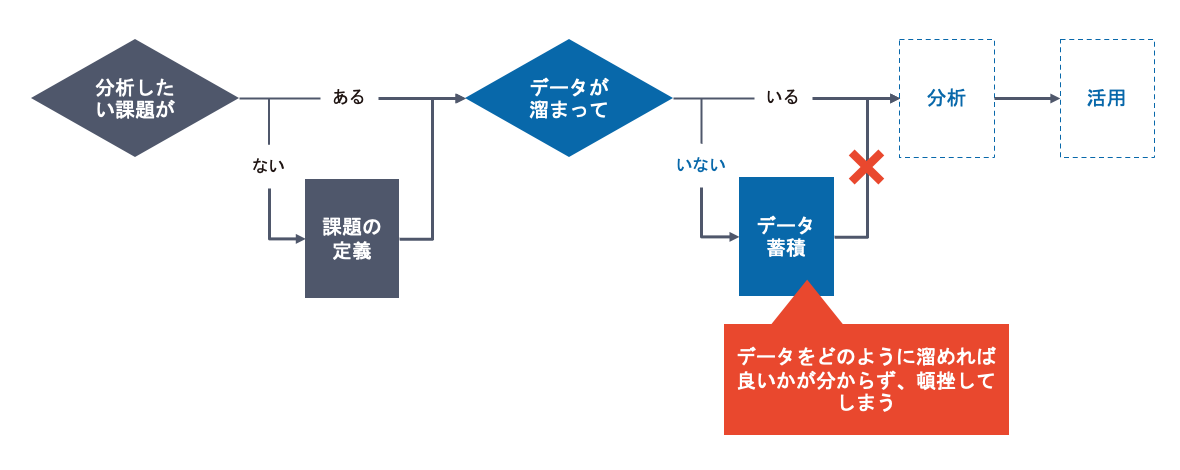
まずは、下記のフロー図を用いて、データ活用の流れを説明します。
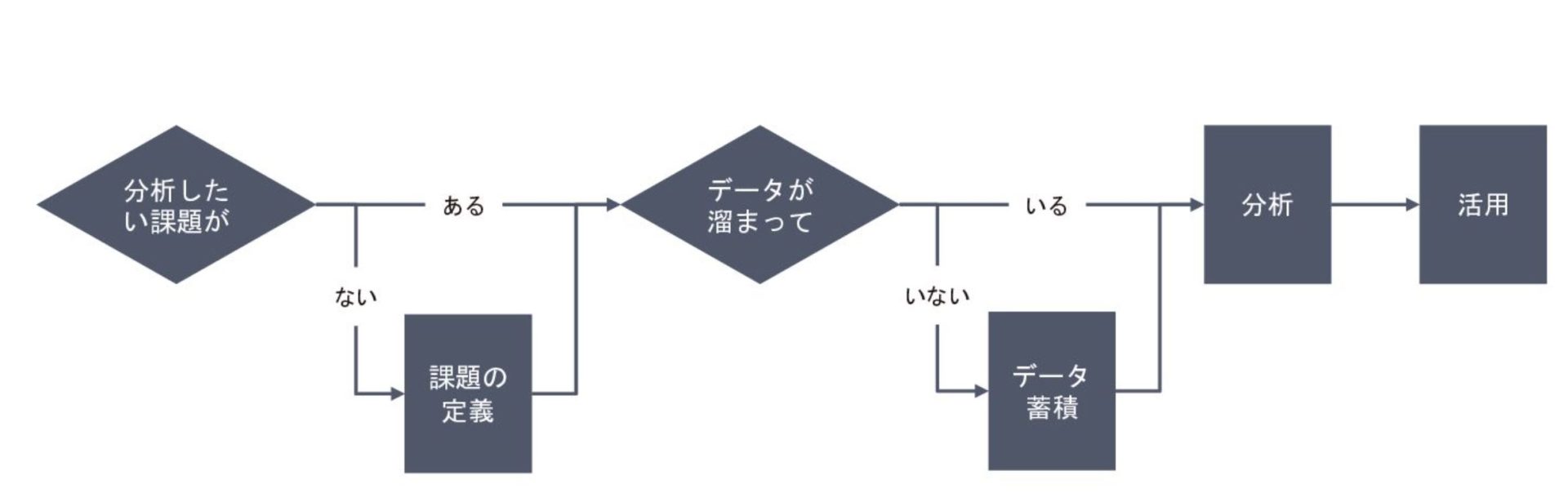
はじめに、分析したい課題を定義し、そのために必要なデータが蓄積されているかどうかを確認します。十分なデータが蓄積されていれば分析を進めますが、データが溜まっていなければまず十分なデータの蓄積に取り組み、その後に分析を行います。
このように、分析したい課題と必要なデータをしっかり揃えて進めるのがデータ活用の基本的な流れです。
このフローを踏まえて、2つの壁を説明します。
データ活用の壁「課題の定義が不十分」
データ活用に立ちはだかる代表的な壁の1つ目は「課題の定義が不十分」であることです。
「多くのデータが蓄積されているので分析すれば何か得られるのではないか」と考えて、目的(課題の定義)が曖昧なままプロジェクトを開始してしまうケースが意外と多いようです。この場合、分析の目的や利用方法が明確ではないため、途中でプロジェクトが停滞することがよくあります。
また、課題が定義できていなければ何を目的としてデータ分析を行うのか説明できないため、関係者との合意形成が難しくなることもあります。
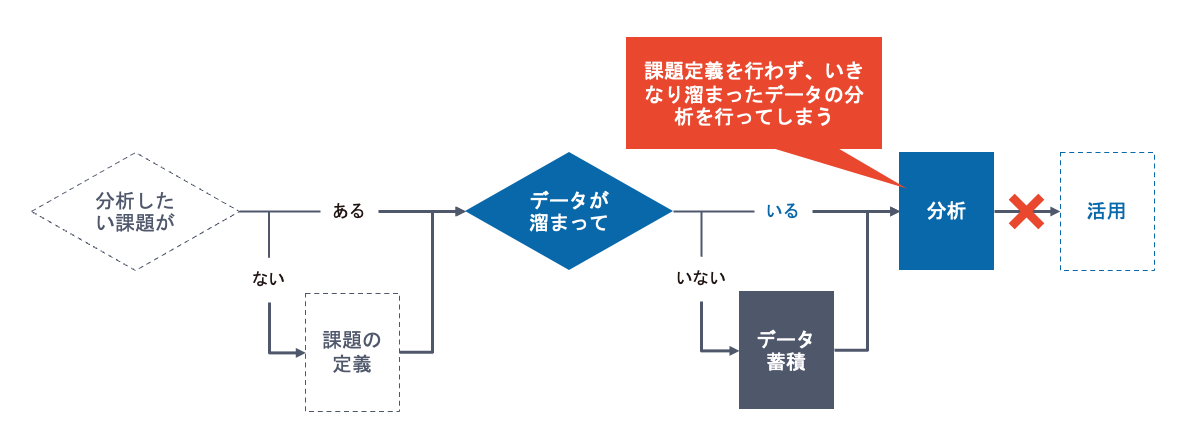
データ分析をはじめてみたが結論も次に何をすべきかもわからないままプロジェクトが終了してしまうケースや、データ分析への投資に対してどのようなリターンが得られるのか効果を明確に説明できずに上層部からの承認が得られないケースは、多くがこの「課題の定義が不十分」であることに問題の根源があると考えられます。
データ活用においては、最初のプロセスとして「課題の定義」が非常に重要です。
分析課題の定義が重要であることは、代表的なデータ分析プロセスのひとつであるCRISP-DMでもはじめのステップとして「ビジネスの理解」が設定されていることからもわかります。
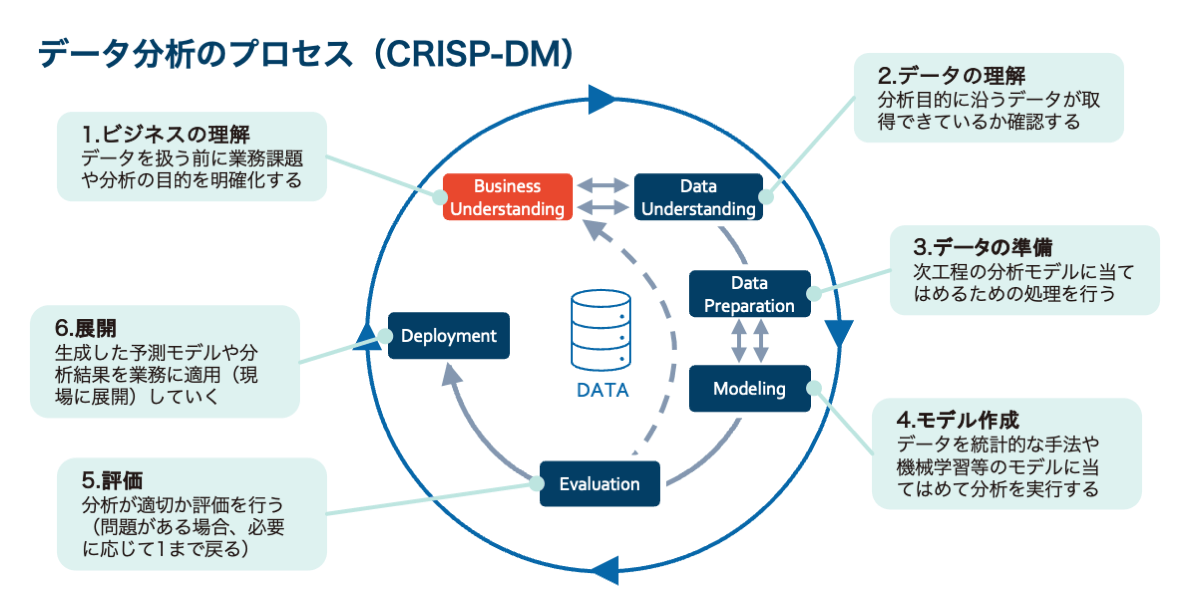
CRISP-DMの「ビジネスの理解」では、業務課題や分析の目的を明確にし、改善すべき箇所やプロジェクトの役割を把握します。見落としがちなポイントですが、データ分析の前段階で重要なのは、データの準備ではなく、ビジネスの理解と課題の明確化です。
これこそがデータ分析のスタートであり、ゴールを見据えるための重要なプロセスとなります。
目的や課題の定義が明確であれば、決裁者への説明がしやすく、承認を受けやすくなります。
また、分析・活用に進んだ際にもより有意義な活動が行える効果が期待されます。
一方で、「課題の定義(ビジネスの理解)」がデータ活用の際に代表的な壁の1つになっているということは、有意義な課題定義を行うのは多くの人にとって難しいことであると示しています。
この段階を曖昧にしてプロジェクトを進めるのは避けなければならないので、自社でデータ活用の「課題定義」を行うのが難しい場合は、コンサルティング会社など専門家の意見を取り入れることも有効です。ただし、外部に丸投げすれば解決するものではありません。
続いて、課題定義をする際に着目すべきポイントを少し紹介するので、参考にしてみてください。
課題定義のためにビジネス理解は欠かせない
ここでは「既存業務の改革」を目的としてデータ活用に取り組むパターンを例としてご紹介します。
既存業務の改革にデータを活用するためには、まず業務の流れや作業手順の中で課題が存在する箇所を明らかにします。ここがボトルネックになって業務効率が落ちているとか、この作業にいつも多量の工数がかかっているという顕在化している課題は見出しやすいと思います。顕在化している課題があれば、関連データを見える化して解決手段を探っていくというその後のプロセスも想像しやすいのではないでしょうか。
しかし、課題が顕在化していなかったり、顕在化した課題の影に別の課題が隠れていたりする可能性もあるので、その場合はヒアリングや調査を通じてデータ分析の対象とすべき課題を発見するところからプロジェクトをはじめることもあります。業務の流れを整理したり現場の意見を調査したりすることで、問題視はされていないが実は改善の余地がある箇所を見出して、改善の可能性を検討するのです。
明らかな課題や改善の余地があるポイントが抽出できれば、次に、そこにはどんなデータが関連するのか、関連データのうち指標となるデータは何で、指標がどのように変化すれば改善につながるのか仮説を立てます。そして、データの相関性などを調べてその指標が変化する要因を特定していきます。
ひとつの課題にひとつのデータが直結しているとは限らないので、複数のデータの関係性を仮説立てして導き出すのがポイントです。
このように業務改革にデータ活用するプロセスひとつを見ても、まず業務課題を見出し「分析課題の定義」をすることで、はじめてその後のデータ分析プロセスが有意義に動いていくことがわかるのではないでしょうか。
「課題の定義が不十分」という壁の乗り越え方は、データを扱う前に自社のビジネスや業務フローを理解している人々の手によって目的を明確にしておくことだといえます。目的が不明確なまま外部のデータ分析の専門家にデータだけを渡してもなかなか有意義な結果は得られません。
NCDCが参画したデータ分析事例の紹介
ここからは、NCDCが参画した実際のプロジェクト事例を用いて、どのように課題の定義をしてデータ活用に取り組んだのか、大まかな流れを説明します。
例1.売上データを営業戦略の最適化に役立てる
1つ目は、食品加工メーカー様の事例です。NCDCが参画した時点で、すでに自社商品の売上データ、オープンデータである生鮮食料品の市場価格データ、気象データの3つのデータを持っていました。
課題は、実績に基づく詳細な営業戦略を立案できていなかったことです。
もちろん「冬は鍋料理関連の商品を売る」など、季節ごとの大まかな営業戦略はありましたが、それだけではデータを活かせていないのではないか。季節性だけでなく気温や生鮮食料品の市場価格など具体的な条件によって売れる商品の傾向を細分化することで、営業戦略を最適化し、売上を向上できるのではないかとの仮説を立てて分析をスタートさせました。
AIを用いてさまざまな商品の売上データと生鮮食料品の市場価格データ、気象データの関係性を分析した結果、例えば、「最低気温がある数値を下回ると商品Aがよく売れる」、「市場の野菜がある価格を超えると商品Bがよく売れる」などといった具体的な情報を得ることができました。
これらの分析結果をもとに緻密な営業戦略を立案し、気温や野菜の価格動向に応じて特定の商品をプッシュするよう営業部門に伝えます。営業の方が分析結果を記した資料を用いて顧客に説明することで、データに基づいた説得力のある商談をすることが可能になりました。
現時点では、この活用方法はアナログな面がありますが、将来的にはリアルタイム通知できるようなシステムを開発し、自動的に営業戦略を最適化することが目指されています。
課題の定義としっかりとした仮説を立案できたからこそ、AIを使って踏み込んだ分析をしたり、活用したりすることができた事例です。
例2.施工データをノウハウの属人化防止に役立てる
2つ目は、建設会社様の事例です。
こちらの建設会社様は、自社で過去に行った工事の施工データを持っていました。
課題は、現場や担当者ごとに工事品質が異なってしまい均質化できていないことと、工事品質を向上させるノウハウが一部の熟練者に属人化していることの改善でした。
そこで、工事現場の情報や施工に関するデータから、施工条件に応じた品質の違いの傾向を把握できるのではないか、AIを用いることで熟練者が持つ暗黙知を可視化して若手にも共有できるのではないかと仮説を立て、分析をスタートさせました。
このプロジェクトはまだ現在進行形ですが、まずは現場の地点、工法、その他諸々の施工条件が施工品質に与える影響をBIツールで可視化することに取り組み、その次にAIを活用してより深層にある情報を可視化することに取り組まれています。
また、このプロジェクトは過去の施工データを活用することからはじめていますが、将来的には工事進行中の現場から施工データを自動的に収集する仕組みを作って分析に取り入れていく計画もあります。そうすることで施工品質の予測精度を更に向上させ、誰もが精度の高い品質予測と最適な施工計画づくりをできるようになることが期待されています。
このように、分析課題や仮説の立案に力を入れることで、データ活用が有意義であるとわかりやすくなるので、関係者の協力が得られなかったり、上層部の承認が得られなかったりしてプロジェクトが止まってしまうリスクも回避できると思います。
データ活用の壁「データの不足」
ここまで1つ目の壁として「課題の定義が不十分」という問題について説明してきましたが、続いて、データ活用に立ちはだかる代表的な壁の2つ目「分析に使用できるデータが不足している」について説明します。
データ活用の必要性は感じているが、使用できるデータがないと考えている方は多いのではないでしょうか。
DXコンサルティングの現場でも「紙の帳票やエクセルファイルのみ存在していて、分析可能な形式でのデータの用意が難しい」「会社からはデータを活用するように言われているが、どのデータをどう貯めれば良いかが分からない」という声をよく聞きます。
データ蓄積のためにはシステム化が必要と考えるかもしれませんが、ExcelファイルやPDFファイルなどデータ形式は問わず、データを持っていれば利用できる可能性は高いです。実際に、数百件のExcelで作られた帳票を分析に活用した事例もあります。
また、近年は文字の読み取り精度が向上しているので、紙の資料しかない場合でもOCRによる読み取りでデータ化が可能な場合もあります。
もちろん、もともと別目的で持っていたデータを分析に利用する場合、一部必要なデータの抜け落ちが発生するような問題は生じがちですが、その場合も使えないデータは削除したり、足りない部分だけを一定のルールで補完したりするデータクレンジング処理を行うことで問題を解決することができます。
データがないと考えていたが、実は利用可能なデータをすでに持っていたというケースは意外とよくあります。
先に「どのデータをどう貯めれば良いかが分からない」という悩みも挙げましたが、これに関しては、1つ目の壁の乗り越え方がヒントになります。
データを貯める際には、活用目的や課題を定義することが重要であり、無計画なデータ収集では効果的な活用をすることはできません。収集すべきデータやその収集方法がわからないということは、そもそも課題の定義ができていない可能性があるので、目的を明確にしてから「どのデータをどう貯めるべきか」決める必要があります。
もしかしたら、新たに大量のデータが必要になると考えていたが、目的を見直したら手元のデータだけでも対応できたということもあるかもしれません。
本当に必要なデータは何かあらためて考える
「分析に使用できるデータが不足している」という壁の乗り越え方は、利用可能なデータやデータ化されていない情報をすでに十分持っているのではないか検討すること、そして、そもそも分析すべきデータの有無を判断できるレベルの課題定義ができているのか振り返ってみることだといえます。
目的のために本当に必要なデータは何かが判断できない場合は、その旨をデータ分析のコンサルタントに相談してみることが有用です。
本当に必要なデータが何かはわかっているのに、そのデータを貯めるために何から始めていいか分からないという場合は、データ取得やデータ蓄積に関する技術面の課題だけをクリアすればいいので、「データをどう貯めれば良いか」とIT部門やシステム開発会社に相談してみるのも良いと思います。
データ分析に関するよくある疑問
最後に、データ分析に関してよく聞かれる質問をご紹介します。
Q:どの程度のデータを貯めればデータ分析ができるかわからない。傾向を見るために必要なデータの母数は一般的にどれくらいか?
A:目的や分析手法により必要数は変わるので、前提条件なしに必要なデータの母数を論じるのは困難です。例えば大規模なWEBサイトのアクセスデータを分析するような場合は簡単に数万件のデータが集められるのではないでしょうか。一方で1年に数件しか実施されない工事のデータを大量に集めるのは不可能です。
できれば1万件以上のデータがあることが望ましいですが、データ収集は一番難しい部分であり、業務の内容によって収集できる件数には大きな差が出てしまうので、件数のハードル設定を高くし過ぎないことも重要です。
目的や分析手法によりますが、少なくとも50件程度のデータがあれば何かしらの分析が可能です。分析によって何を得たいのか課題の定義さえしっかりできているのであれば、データの形式や量に捉われ過ぎずに、手元にあるデータから何かしらの活用方法を模索してみるのも良いと思います。
Q:データ活用の目的は明確でおそらく十分なデータも持っているが、専門知識が不足しており十分にデータを活かせない。どんな分析手法を採用したらいいのかがわからない。
A:分析手法について専門知識がない場合は、自分でやることにこだわらずまず専門家に相談してみることがお勧めです。
また、scikit-learn(サイキット・ラーン)というPythonで使える機械学習用のライブラリがあるのですが、その「アルゴリズムチートシート」を活用すると分析手法を選びやすくなるので、まず自分で分析手法を考えてみたいという方は参考にしてください。
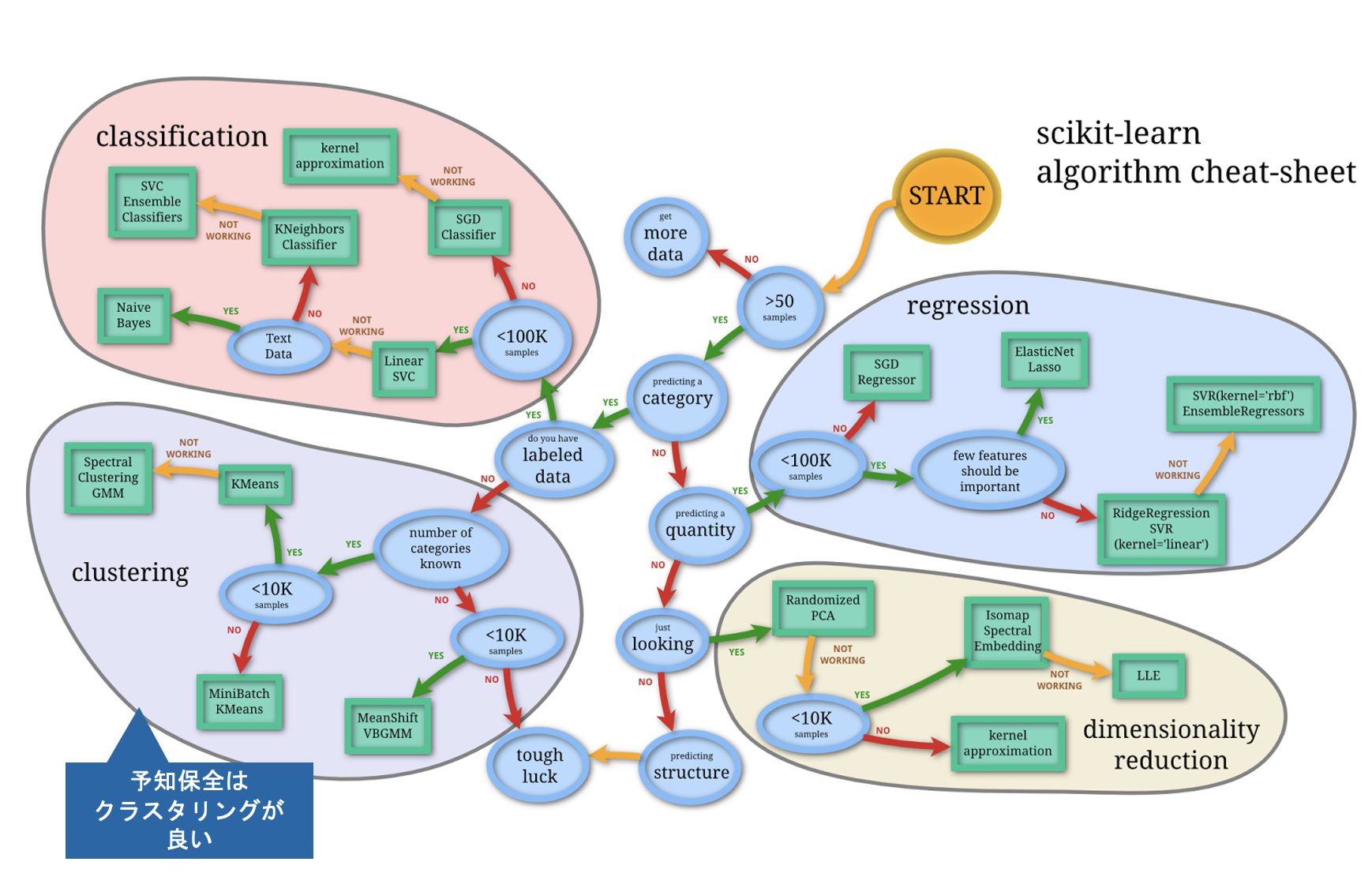
scikit-learnの図を見ると「labeled data」が「yes」なら「classification」へ、「no」なら「clustering」へ分岐していますが、これはラベルデータがある場合は分類問題や回帰分析が適用されますが、ラベルがない場合は教師なし学習のクラスタリングを使用することを意味します。
例えば「工場機械の故障予知をしたいがラベルデータ(故障データ)が不足している」という場合はこの教師なし学習が用いられます。クラスタリングにより、データを何次元かのクラスタ(グループ)に分類していくことで、故障する傾向のあるデータが特定のクラスタ(グループ)に属することを見出せれば、属性が近いデータを予測検知して予知保全に役立てられます。
このようにデータの分析手法は、データの特徴や目的に合わせて適切なものを選ぶことがとても重要です。
データ分析やDXのご相談はNCDCへ
NCDCは、データ分析に際しての課題定義、分析実務、分析結果に基づいたビジネス戦略の策定、新たなシステムの設計構築まで、さまざまな分野のスペシャリストによるワンストップでのご支援が可能です。また、データ分析を含むDXコンサルティングや新規サービス実現コンサルティング、内製化支援など幅広くサポートしています。データ分析やDXに関するご相談がある方はぜひお問い合わせください。