目次
収集できるデータ量が増え続ける現代においては、人手に依存せずデータを迅速に処理できるAIをビジネスに取り入れる重要性がますます高まっています。
AIの中でも、本記事のテーマである機械学習(ML: Machine Learning)は、膨大なデータをコンピューターに反復学習させることで、データの特徴や規則性を見つけだす手法として有名です。MLモデルを製品やサービスに導入することで、より精度の高い推論が可能になります。このため、データに基づく意思決定の迅速化や業務の効率化に繋がり、競争力の強化が期待できます。
しかし、MLモデルを開発しても、実際の運用ですぐには期待通りの成果が得られなかったり、運用の複雑さが課題になったりするケースは少なくありません。ビジネスでMLモデルを活用するには単にシステムを開発するだけでなく、運用環境で継続的に機能し、必要に応じて改善できる仕組みが求められます。
この仕組みを支えるのが「MLOps(エムエルオプス)」です。
MLOpsとは?
MLOpsとは、MLとOperations(運用)を組み合わせた言葉で、モデルの開発から運用までの一連のプロセスを効率化し、継続的に最適化するための考え方や仕組みを指します。
MLOpsが生まれた背景は、ソフトウェア開発におけるDevOpsが生まれた背景と非常に似ています。DevOpsは、開発と運用の分断による課題を解決するために生まれました。MLの分野でも同じように、これまで運用作業は専任のエンジニアが行うことが一般的であったのが、クラウドサービスの発展により、データサイエンティストが運用の一部を担うケースが増えてきました。その結果、モデルの開発と運用の境界が曖昧になりつつあり、開発と運用を円滑に連携させる手法としてMLOpsが注目されています。
DevOpsについて知りたい方は、こちらの記事も合わせてご参照ください。
MLOpsにおける主な手法
MLOpsに含まれる考え方や仕組みは様々ありますが、ここでは代表的なものを4つご紹介します。
- MLパイプラインの自動化
MLパイプラインとは、データの前処理、モデルの学習、評価、デプロイといった一連のワークフローのこと。これを自動化することにより、手動での介入を減らし、エラーを最小限に抑え、効率的にデプロイすることができる。特に、学習データが頻繁に変わる場合や、モデルの再学習が定期的に必要な場合に効果的。 - 監視とアラート
モデルの性能とデータの品質を継続的に監視し、異常が発生した場合にアラートを通知する仕組み。監視する理由は、運用中のモデルの性能が時間とともに劣化する可能性があるため。- 劣化する状況の例
- データドリフト:推論時に、モデルの学習時と異なるデータ分布が入力されることで推論精度が低下する。
- コンセプトドリフト:推論すべき値の定義や意味が時間とともに変わる。
- データ品質の問題:入力データに欠損値や異常値が増加し、モデルの精度が低下する。
- 劣化する状況の例
- MLモデルのバージョン管理
モデルの変更履歴を明確にし、どのデータやパラメータで作られたかを整理して保存する仕組み。これにより、どのバージョンのモデルがいつ、どのように作成されたのかを追跡でき、再現性や品質管理を向上させることができる。また、本番環境で新しいモデルが予期しない動作をした場合、すぐに過去の安定したモデルに戻すことができる。 - CI/CD:継続的インテグレーション/継続的デリバリー
開発したコードのテスト、ビルド、デプロイを自動化することで、エラーを減らし、リリースサイクルを短縮する。MLパイプラインにCI/CDを組み込むと、機械学習モデルのコードや関連するデータの変更が本番環境に安全かつ迅速にデプロイできるようになる。
MLOpsとMLパイプラインの自動化
MLOpsにおける主な手法をいくつか紹介しましたが、その中から今回はMLパイプラインの自動化について詳しく説明します。
MLパイプラインの自動化のメリット
MLパイプラインを手作業で運用した場合を考えてみましょう。データの前処理やモデルの学習、デプロイを毎回手動で行うと、作業負担が大きくなり、時間もかかります。本番環境へのデプロイ時にファイルを誤って移動したり、旧バージョンのモデルを誤って使用するリスクもあります。
また、手動運用ではモデルの更新が遅れ、精度が低下しやすくなります。特に市場の変化が激しい分野では、頻繁な再学習が必要ですが、手間がかかるため対応が遅れがちです。属人化も大きな問題で、特定の担当者がいなければ運用が滞るリスクがあります。
さらに、一貫性の確保も難しく、担当者ごとに学習環境やデータ処理が異なり、再現性が失われることもあります。
MLパイプラインを自動化すれば、作業負担を減らし、精度を維持しながら効率的に運用できます。MLパイプラインの自動化は、MLOpsの実践において中心的な役割を果たしているのです。
MLOps導入は小さく始めて段階的に拡張する
最初からデータの前処理〜デプロイまでの全てのステップを自動化しようとすると、開発コストがかかり過ぎる上に、予期しない問題が発生した際にどこに問題があるのかを特定するのが難しくなります。特に、MLOpsの導入初期段階では、小さく始めて段階的に拡張することが望ましいです。
例えばAmazon SageMakerを活用すると、この段階的な自動化がスムーズに進められます。まずはモデルの再学習の中心的なステップとなるデータの前処理とモデルの学習の自動化に取り組もうと考えたとします。
SageMaker Processingは、任意のPythonコードをコンテナ上で実行するジョブ※1を作成できます。作成する際は、処理したいデータやインスタンスタイプ、コンテナイメージ等の条件を指定できます。これを利用することで、大規模データの前処理をマネージドな環境でスケーラブルに、かつ一貫した環境で実行できます。
※1. ジョブ:処理開始時にコンピューティングインスタンスが自動起動し、処理が完了すると自動停止して削除される。使用した分だけ秒単位で課金されるため、コスト効率よく処理できる。
なお、SageMaker Processingは前処理や評価のステップ等に使用されることが多いですが、任意のPythonコードを実行できることから、モデルの学習にも利用できます。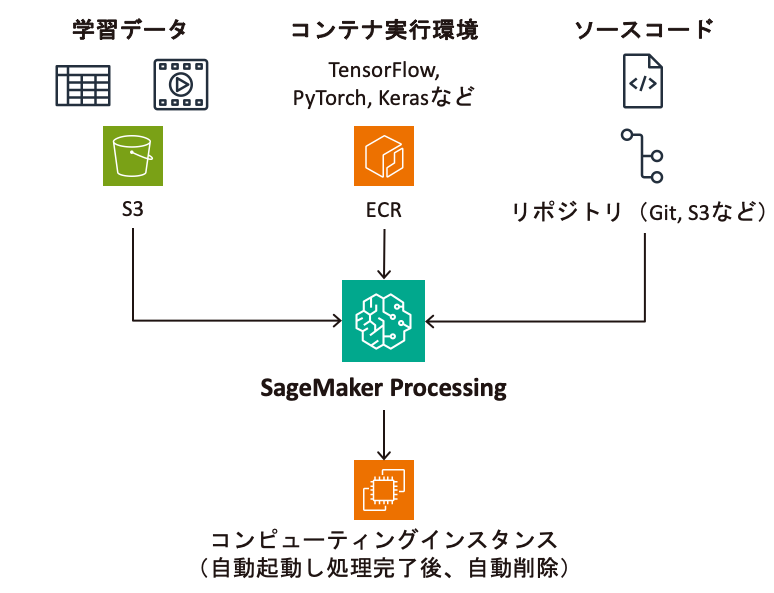
SageMaker Pipelinesを利用すると、データの前処理が完了してからモデルの学習が開始されるように、ジョブ実行の順序を自動的に制御できます。データの前処理ジョブが完了した後にのみモデルの学習ジョブが実行されるように設定できるため、不完全なデータでモデルを学習してしまうリスクを軽減できます。
SageMaker ProcessingやSageMaker Pipelinesの設定は、SageMaker Python SDK、Amazon SageMaker Studioのビジュアルパイプラインデザイナー機能(GUI)などを使用して行えます。デザイナー機能によりエンジニアではない方もMLパイプラインを構築することができます。
データの前処理ジョブとモデルの学習ジョブを作成し、それらを統合したMLパイプラインが以下の図になります。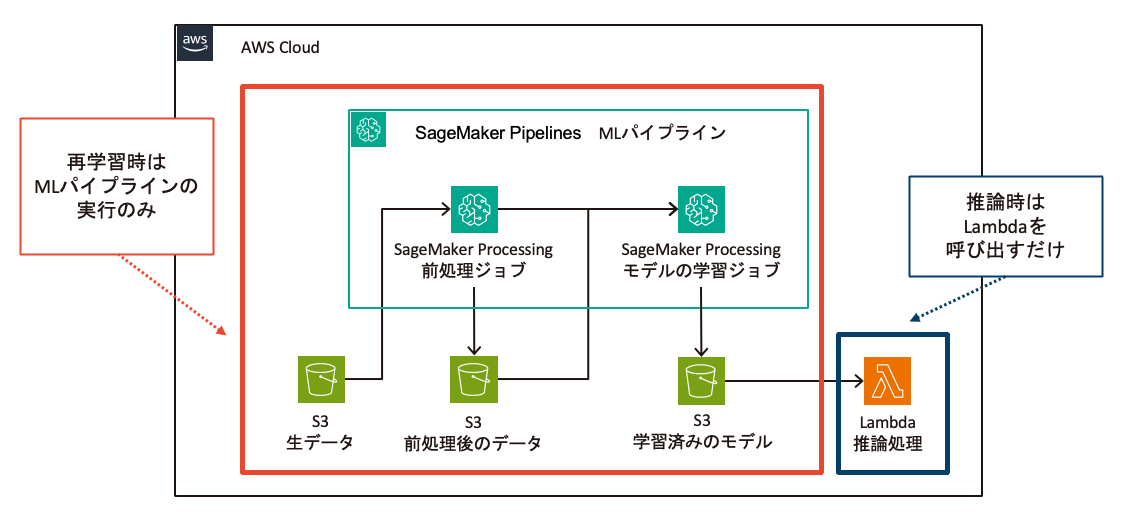
これにより、データの前処理とモデルの学習を手作業で実行する必要がなくなり、運用の負担を軽減できそうです。また、一貫した手順で処理が行われるため、予期せぬエラーを防ぎ、モデルの品質を安定させることが期待できます。
さらに、EventBridge SchedulerによるMLパイプラインの定期実行やSageMakerエンドポイントへのモデルのデプロイ、モデルの学習ジョブの作成により適したSageMaker Trainingの活用に取り組んでみると良いでしょう。
MLパイプラインの自動化の実例
ここからは2つの実例を用いて、MLパイプラインの自動化について説明します。
技術的な話や専門用語が増えますが、そこまで詳しい知識がない方でも、どんなツールがあって何ができるのかイメージを掴んでいただくことはできると思います。
例1. AWS上のMLパイプライン自動化例
1つ目の実例は、MLOps導入の最初のステップとして、データの前処理とモデルの学習を自動化したものになります。こちらはAmazon SageMaker AIを利用しました。
SageMaker Processingでデータの前処理ジョブとモデルの学習ジョブを作成し、SageMaker Pipelinesで各ジョブを統合したMLパイプラインを作成しています。さらに、EventBridge SchedulerによるMLパイプラインの定期実行、Lambdaによる推論処理を行っています。
こちらの事例では、モデルの開発が完了したばかりであり、かつ開発時に使用したデータが非常に少ないことで今後取得するデータと傾向が大きく異なる可能性がある状況でした。そのままでは、モデルの精度が低下して実運用に適さなくなる可能性があるため、新たに得られるデータを継続的にモデルに反映できる仕組みを早い段階で整えることを最優先事項とし、このような構成として仮運用していくことにしました。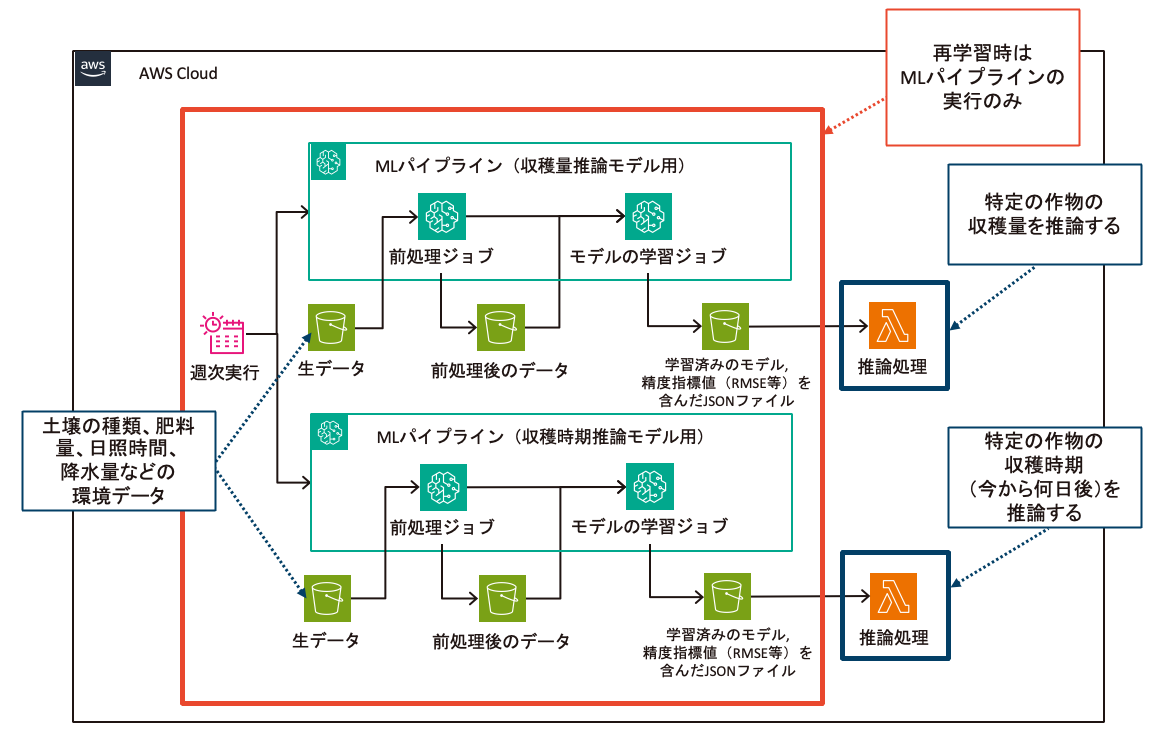
メリットとしては以下が挙げられます。
- 使用するAWSサービスが比較的少なく導入しやすい。
- データの前処理とモデルの学習を手作業で実行する必要がなくなり、運用の負担を軽減できる。
- 一貫した手順で処理が行われるため、予期せぬエラーを防げる。
- MLパイプラインの定期実行により、最新のデータをモデルに反映させることができる。
MLパイプラインの自動化の観点からみたデメリットとしては以下が挙げられます。
- Lambdaに取り込めない大きさのモデルファイル容量になった場合に推論処理ができない。
- 再学習した結果精度が低下した場合にそのモデルで更新されてしまう。
例2. Azure上のMLパイプライン自動化例
2つ目の実例は、Azure Machine Learningを使用してデータの前処理〜デプロイまでを自動化したものになります。
データの前処理ジョブとモデルの学習ジョブに加えて、評価ジョブ、モデル保存を統合したMLパイプラインを作成しています。Azure Web AppsやAzure Functionsにモデルファイルを取り込むのではなく、推論エンドポイントとしてモデルをデプロイするようにしています。ワークスペース内にモデルを保存することでモデルのバージョン管理が行えます。推論エンドポイントを使用する際に、Azure Monitorを通して推論結果や入力値を保存でき、アプリケーションや分析で確認できるようにしています。
こちらの事例もモデルの開発が完了したばかりでしたが、大量のデータを用いて開発することができたため、より実運用に近い状況を想定した構成をとりました。
なお、Azure MLについてもAzure ML Python SDK、Azure ML Studio デザイナー(GUI)などを使用してMLパイプラインの設定が行えます。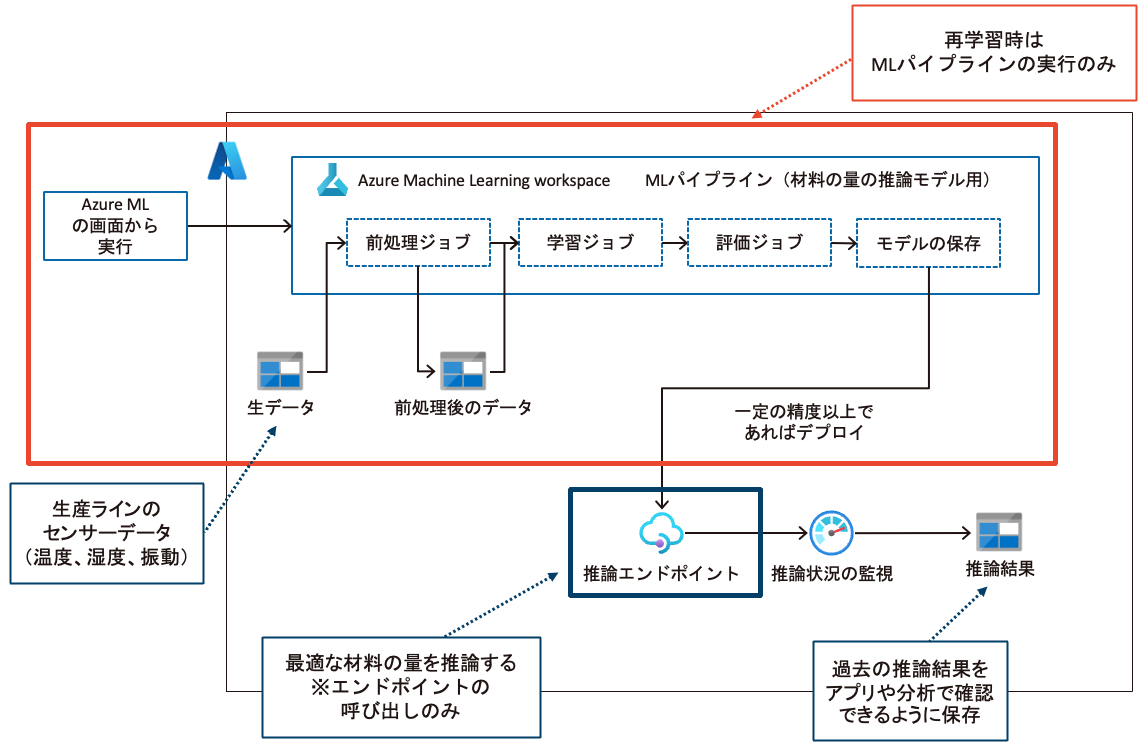
メリットとしては以下が挙げられます。
- データの前処理からデプロイまでを手作業で実行する必要がなくなり、運用の負担を軽減できる。
- 一貫した手順で処理が行われるため、予期せぬエラーを防げる。
- 新しいデータの追加に応じて自動でモデルを更新できるため、素早く最新の傾向を反映できる。
- モデルのバージョン管理やどのバージョンのモデルがいつ、どのように作成されたのかを追跡できる。
- モデルファイル容量が大きくなってもそれに合わせて推論エンドポイントとしてデプロイできる。
- 再学習した結果精度が低下した場合にそのモデルで更新されず、精度を保つことができる。
- 推論エンドポイントは、複雑なモデルの詳細を隠し、シンプルなAPIを提供する。これにより、エンジニアはモデルの内部構造を知らなくても、推論機能をアプリケーションに組み込める。
- アプリケーションのコードの更新と推論エンドポイントの更新が完全に分けられ、デプロイする範囲が極小化されている。
MLパイプラインの自動化の観点からみたデメリットとしては以下が挙げられます。
- Azureによって必要に応じて、MLパイプライン内の個別のコンポーネントがアップグレードされたり※2、Python SDKを使用している場合にバージョンがアップグレードされたりするため、MLパイプライン自体のメンテナンスは継続的に必要になる。
- 最新のデータの傾向がモデル学習時と異なる状況が続くと、再学習する意味がなくなる。データドリフトを監視しておいてアラートを上げる仕組みを導入するなど、MLパイプラインの自動化以外の仕組みも検討する。
※2. MLパイプラインのジョブの内容が書き換えられるというわけではなく、ジョブの作成や実行などを担うAzure サービスのコンポーネント自体がアップグレードされるということ。
MLモデルの開発やMLOpsはNCDCにご相談ください
MLOpsのメリットやMLOps導入のイメージを掴んでいただけたでしょうか?
NCDCでは、AI活用を含むさまざまなデジタルサービスの企画からシステム開発まで一元的にご支援しています。MLモデルやMLOpsの導入についても、豊富な経験に基づく実践的な計画、開発、そして運用の支援まで行っていますので、この記事を読んで興味を持ってくださった方は、ぜひお気軽にご相談ください。