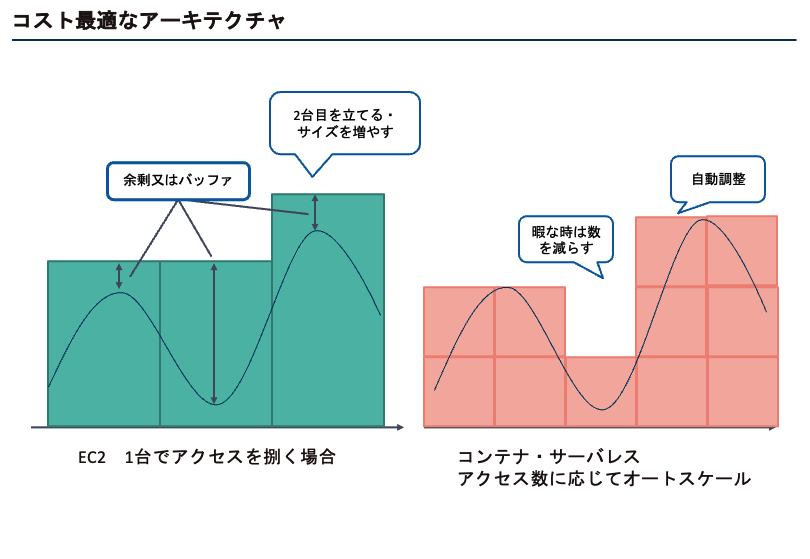
目次
2024年1月31日にオンラインセミナー『クラウドネイティブ時代のシステム運用・監視とは? 自動化・効率化のベストプラクティスを紹介』を開催いたしました。
この記事では当日用いた資料を公開しています。
クラウド時代の運用監視
はじめに、オンプレの基盤からクラウド基盤(AWS)に移行したあるシステムの運用監視事例をご紹介します。
オンプレミスの場合の監視業務
JP1等の統合監視ツールを使ってオンプレの基盤を監視していました。
監視ツールからアラートが出ると、24時間365日対応の運用監視担当のベンダーがエラーを調べて、手順に基づいて再起動などを実施します。再起動しても復旧しないものやアプリの修正が必要なものは、運用監視担当からインフラ担当やアプリ担当にエスカレーションするという運用をしていました。
オンプレでは上記のようにアラート対応が手動作業中心でしたが、クラウド基盤での運用監視はどう変わるのでしょうか。
クラウド(AWS)の場合
オンプレの時と同様にシステムを監視するのですが、JP1などの監視ツールを入れる必要はなく、AWSが提供している監視サービスを利用可能です。問題が生じればアラートが出ますが、人間(監視の担当者)が対応するのではなく、あらかじめ定めたルールに基づいて再起動、オートスケール、リトライなどを行い「自動復旧」を試みるのが最初のステップになりました。
自動復旧で対応できないケースは、ルールに基づいて「自動的」にアプリ担当やインフラ担当にエスカレーションされます。
オンプレの場合はまずエラーを切り分けて復旧作業をしたり、適切な担当チームにエラーを伝えたりする人が必要でしたが、クラウドではこの役割を自動化したため「24時間365日対応の運用監視担当チーム」が不要になっています。これは大きなコストカットにつながります。
もちろんすべてのシステムがこの事例と同じように「運用監視チーム」をなくせるとは言いませんが、クラウド利用によって運用監視業務のかなりの部分は自動化できる可能性があります。
まず事例をご紹介しましたが、このあとその背景をもう少し詳しく説明していきます。
クラウドは異常の自動解決がサービスに含まれる
オンプレミスでの運用は、当たり前ですがサーバーの面倒をすべて自分たちでみます。保有するすべてのサーバーを対象として、多くの数値を監視する必要があります。ディスクI/O、CPUメモリー、ディスクの残量、ネットワークインアウトなどなど、監視する項目は多数あり、自力で監視する必要がありました。異常検知も大変なので前述のJP1などの専用ソフトウェアが必要になります。
オンプレの運用でも対応を自動化できる部分がゼロではないですが、運用監視の設計が非常に難しいため、ある程度は自動化しても結局は手動での再起動などの作業が残ってしまい、そのための監視チームを置いているケースが多いのではないでしょうか。
もちろんオンプレの場合は、ソフトウェアの監視だけでなく保有するサーバーの物理的なメンテナンスも必要になります。
オンプレと比較した場合、監視で異常が出た時に自動で解決してくれることが多いのがクラウドの特徴だといえます。
自動解決すること自体がサービスに含まれているので、ユーザーが自分で対応すべき対象が少なくなります。自動復旧によるオペレーションの削減に加えて、そもそもクラウドでは監視すべきポイントが少なくて済むことも重要です。監視対象が少なく監視の仕組みがシンプルになりやすいので、自動化がしやすいといえます。
続いて、そうしたクラウドならではの恩恵を多く受けられるサーバレスやマネージドサービスの特徴をご紹介します。
サーバレス
例えばAWS Lambdaなどのサーバレスのサービスを使ってアプリケーションを実行している場合、アプリのクラッシュを自動で監視し、デフォルトの機能で規定の起動数まで再実行してくれます。監視ツールのアラートを受けて人が手動対応する必要はありません。
アクセス急増時にはオートスケールアウトというかたちで同時実行数を自動で増やして対応してくれます。これも人が急いで対応することなく、自動的に解決した後でログを見て事象を確認するのが人の作業になります。
サーバーのディスク容量が一杯になるような問題もサーバレスでは起こりません。もちろん設計次第の部分はありますが、基本的にはディスク容量などを考慮する必要はないと考えてかまいません。
マネージドサービス
クラウドサービスの中には、ログの監視すら行わなくて良いマネージドサービスも存在します。例えばDynamoDBのようなマネージドサービスのデータベースにはCPUやメモリという概念がないためCPUやメモリの使用率を管理する必要がありません。「CPU使用率が上がってきて危ない」というような問題を一切気にしなくていいのもマネージドサービスの強みです。
サーバレスやマネージドサービスを使えば使うほど監視が楽になるのが分かっていただけるのではないでしょうか。
とはいえ、クラウドサービスがすべて異常を自動解決してくれるわけではないのでもちろん監視が必要なものも存在します。
クラウドでも監視が必要なもの
先ほどDynamoDBというデータベースにはCPUやメモリという概念がないと紹介しましたが、同じAWSのデータベースでもAmazon RDSはCPUやメモリを管理するという概念があり、一定の監視が必要です。
また、サービスの死活監視は必要です(ただし、ヘルスチェックのサービスがあるので半自動で対応は可能です)。
運用監視の中で自動化するのが難しい領域として残るのはアプリケーションエラーです。
アプリの問題は人が確認しないとわからないことが多いため、オンプレでの運用と同じように監視して、アラートが出たら人が対応するという体制が必要になると思います。
ただし、運用監視を専門としたチームをつくってもアプリのエラーに対してできる対応はそう多くないので、アプリのエラーが出たらそのままアプリケーションチームにエスカレーションすると割り切ることは可能です。その場合、ルールを決めて通知の仕組みを自動化してしまえば、「24時間365日対応の運用監視担当チーム」のようなものは必要なくなります。
クラウドには監視の仕組みが用意されている
運用監視面でのクラウドのメリットとして、監視の仕組みがすぐ組めるようサービスが備わっていることも挙げられます。
AWSの場合はAmazon CloudWatch メトリクスというサービスがあり、必要な項目をほとんど網羅しています。Amazon CloudWatch メトリクスで「ある値がこれ以上になったらこうアクションする」という風に条件を設定できるので、対応の自動化が非常に簡単であり、一度設定してしまえばそれで監視の設定は終わりというようなものが多いです。
ある条件になると自動で再起動するというルールでも、ある条件ではこのコマンドを実行するというようなルールでも簡単に設定して自動化できます。
アプリケーションログに関してはログ監視のAmazon CloudWatch Logsというサービスがあり、ログが集約するようになっています。もしエラー文言のあるログが入ってきたら再起動するとか、アプリ担当に通知するといったアクションを決めて、簡単に監視の設定をすることができます。
このようにアプリの監視にもAWSがデフォルトで備えるサービスを活用できます。
Amazon ECSの監視例
次にAmazon ECSというコンテナサービスにおける監視を例に、よくある監視項目について説明します。
CPU使用率とメモリ使用率は一定値以上になるとAmazon ECSがオートスケールして解消してくれるため監視は不要です。オートスケールでコンテナが1台から2台になることによって負荷が分散されてCPUとメモリの使用率は自動的に下がります。オートスケールで自動的に解決するので、この問題はアラートを出す必要もないといえます。
ディスク使用率はステートレスになっていれば監視は不要です。
死活監視もAmazon ECSが行い、自動で再起動してくれます。Application Load Balancerで正常なレスポンスを返すかどうかもチェック可能なため、これを利用して異常時の対応を自動化することも可能です。
遅延については監視が必要です。サーバレスポンスが遅い時は監視してアラートを出すことは必要で、これは数少ないクラウドでも監視すべき項目として残ります。
ただし、再起動で解決する可能性が高いものに関してはそのように設定を行うことで半ば対応の自動化も可能です。
アプリログも監視が必要です。先に紹介した通りアプリに関してはエラー対応の自動化が難しいため、きちんとエラーログを見てアプリ担当者が対応することが求められます。
インフラのログに関しては、クラウドはマネージドサービスになっているので基本的に見る必要がありません。
このようにAmazon ECSでサービスをホストする場合は、運用監視でエラー通知を受けて人が何か作業するものがほとんどない(アプリケーションエラーぐらいしかない)ことがわかります。
賢く使いたい「自動」監視サービス
ここまで主にAmazon ECS等の個別サービスについて紹介してきましたが、さらにAWSにはサービス横断で自動監視を行ってくれるサービスが存在するので、これらを用いた運用監視やセキュリティのチェックが可能です。
昔は監視の仕組みを自分で作らなければならなかったようなことも自動で検知してくれるサービスがあるので、いくつかご紹介します。
Amazon GuardDuty
脆弱性の動的検知をしてくれます。具体的には悪意のある攻撃やマルウェアがインストールされて起きる異常な挙動などを自動検知してくれます。
Amazon Inspector
脆弱性の静的診断をしてくれます。動的検知のAmazon GuardDutyとは対になるもので、アプリケーションの脆弱性を自動で検知してくれるサービスです。こうした自動検知のサービスでセキュリティを高められるのもクラウド利用のメリットです。
Amazon Macie
機械学習による機密データの検出、分類、保護を行ってくれます。保存データ内に機密データがあるかどうか、データの方が適切にされているかを検知してくれます。
Amazon DevOps Guru
AIによって障害を自動検知できます。障害が起きたら基本的にはエラーログが出ますが、稀にエラーログが正しく出ずに障害が起きてしまっているケースもあります。そのようなパターンをAIで自動的に検知して報告してくれます。
AWS Cost Anomaly Detection
コストの異常が検出できます。通常とは異なるコストが発生した場合に通知が来るもので、
例えば第三者に勝手にリソースを作られて仮想通貨のマイニングをさせられていたというような問題を早期発見できます。
AWS Security Hub
セキュリティに関するアラートを集約し、まとめて確認できるようになります。異常の有無が一目でわかり、特定の結果に対する自動修復なども容易になります。
こういったサービスによって運用監視の隙間を補強できるのは重要なポイントです。
クラウドサービスを使うと、自分たちで意識的に監視しようと思って設計したところに加えて、自動監視サービスが意識してなかったセキュリティの穴や障害をキャッチして通知してくれます。つまりクラウドは監視の強度も高めやすいといえます。
ここで紹介したもの以外にも自動検知の仕組みがあるので、それらを活用することによってより強固な体制を作れると思います。
まとめ:クラウド時代の運用監視とは?
クラウド上に築いたシステムは、クラウドサービスがもともと備えている運用監視を楽にするサポートを享受できます。
ただし、クラウドであれば何でも同じという意味ではありません。クラウドネイティブなシステムになるほど運用監視が楽になります。
簡単に言うと先に紹介したサーバレス、コンテナ、マネージドサービスを活用しているものがクラウドネイティブな状態です。そもそも監視すべき項目が少なく、復旧対応のほとんどが自動化されるのでクラウドネイティブ度が上がれば上がるほど運用監視が楽になっていきます。
クラウドサービス内で必要なものが網羅されているので追加のツールを用いて自前で監視の仕組みを構築する必要がないのも大きなメリットです。用意されているものをカスタマイズして再起動やコマンド実行などの自動対応を設定することで、ほとんどの作業は自動化できます。
監視チームがシステムを見守り、アラートが出たら人間がエラー内容を見てマニュアル対応するようなものがかなり少なくなっています。
もちろん人の手による対応が必要な部分はありますが、自動対応できるものは自動化することで、本質的なアプリケーションエラーへの対応や重要な障害への対応にリソースを集中できるのが「クラウド時代の運用監視」の在り方だといえます。
クラウドを活用した運用・監視手法のご相談はNCDCへ
NCDCは、クラウドネイティブなシステムの設計や、柔軟なシステム運用を可能にする先進的な開発手法などの知見・技術を有しており、マネージドサービスをうまく活用した運用監視業務の効率化をサポートすることが可能です。
クラウド監視の方式を検討されている方、効率化にお悩みの方は、ぜひ一度NCDCにご相談ください。