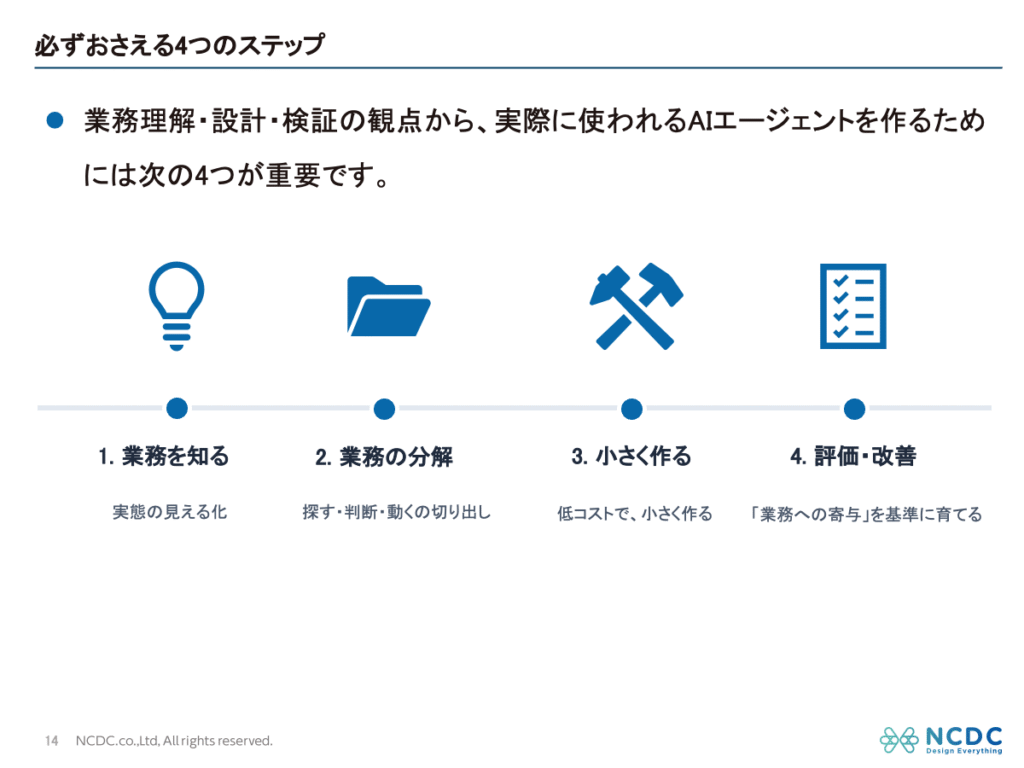
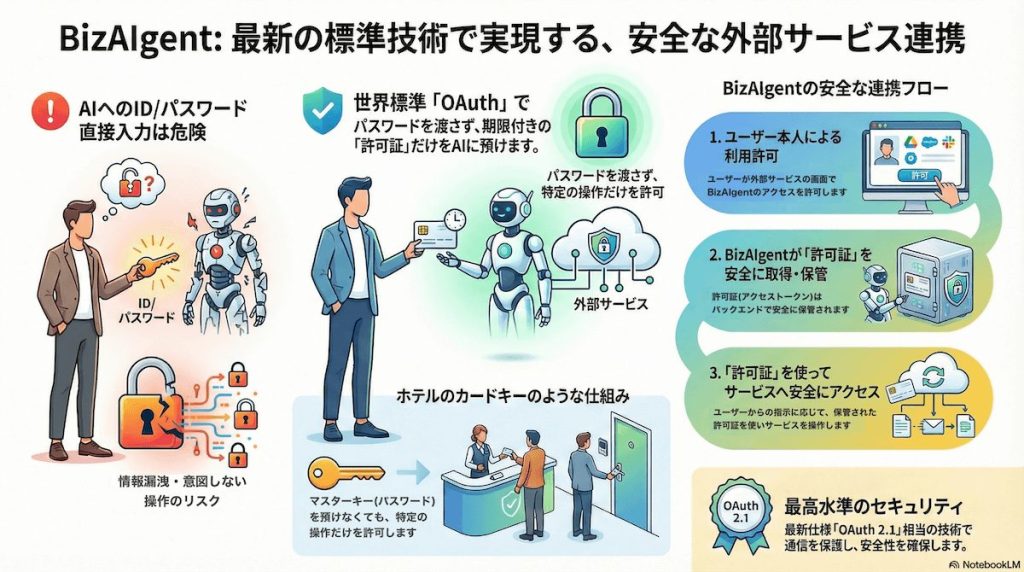
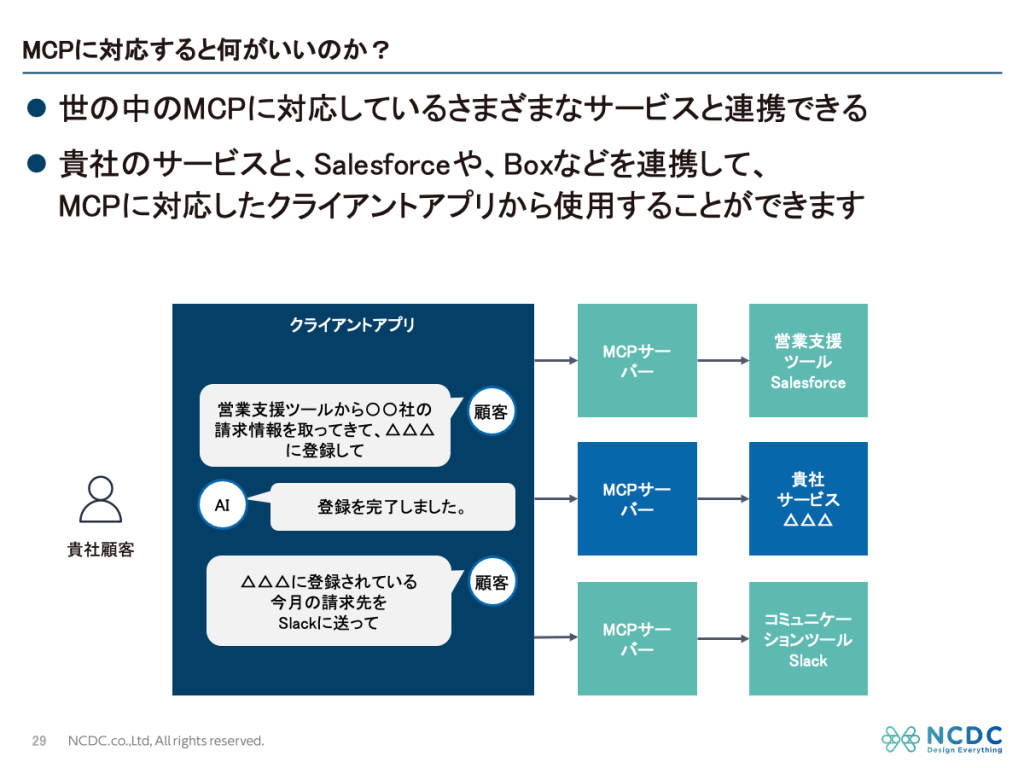
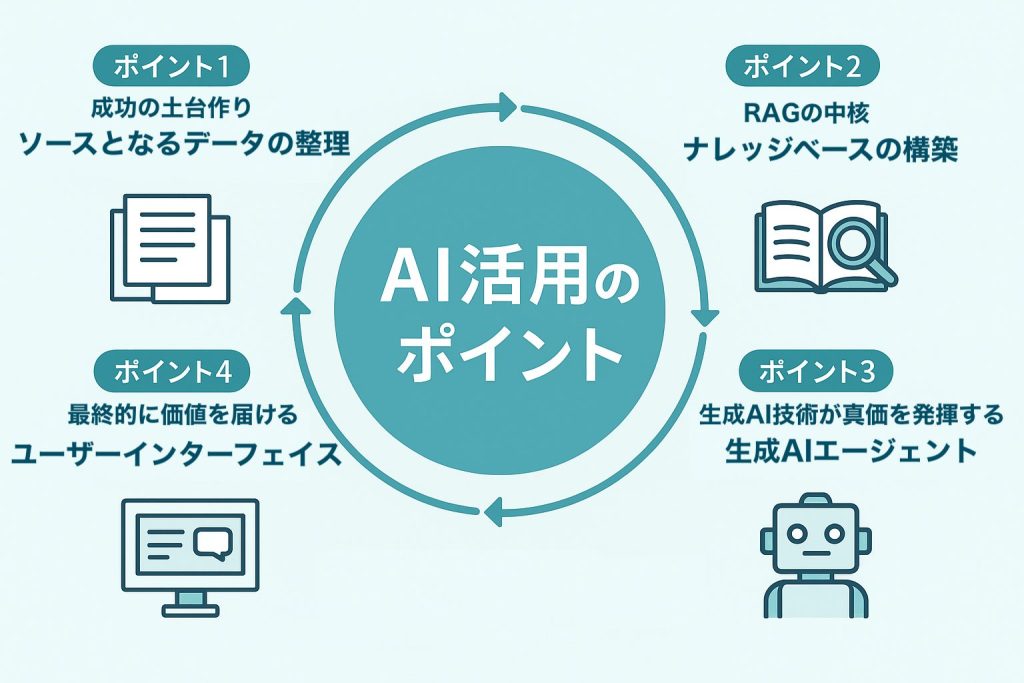
目次
本記事では、ChatGPTに代表される大規模言語モデル (LLM:Large Language Models)に独自のデータを組み合わせることで、実用的なテキスト生成AIサービスを作る方法をご紹介します。
LLMを用いた生成AIとは?
ChatGPTの登場以降、LLMを使った生成AIはニュースにならない日がないくらい急速に利用者が拡大しており、またその技術も日々進化し続けています。
LLMとは自然言語(人が日常の対話で使用することば)での入力を理解して、人間が書いたような文章を生成して返すことができるAIです。LLMは大規模言語モデルという名のとおり膨大なテキストデータから言語のパターンを学習しているため、機械的なぎこちない表現ではなく、人が自然な対話だと感じられる精度の高い文章を生成することができます。
OpenAIが2022年11月30日に公開した「ChatGPT」がもっとも有名ですが、その後、 Microsoftの「Bing AI」、「Microsoft Copilot」などChatGPTのような技術を用いたサービスも次々とリリースされています(MicrosoftはOpenAIに多額の投資を行い連携しています)。
また、Googleは独自の対話型AIサービス「Bard」を提供しています。
(2025年4月追記)ChatGPTの登場以降、わずか数年で生成AI技術は飛躍的に進化しています。主要な生成AIモデルの2025年4月時点の最新状況について追記します。
「ChatGPT」の最新モデルでは、より高速で高精度な応答が可能となるのに加えてマルチモーダル(画像・音声も統合的に扱える)能力が大幅に強化されています。
ChatGPTの有力な競合として「Claude」が台頭しており、特に長文処理や複雑な指示に対する理解力が評価されています。
Googleの「Bard」は「Gemini」にブランド変更され、モデルも刷新されました。またGoogleの強みである検索エンジンやGoogleのサービスとの連携も強化されています
「Bing AI」は「Microsoft Copilot」に統合され、モデルの性能向上に加えてWord、ExcelなどのMicrosoft製品との連携が強化されました。
ChatGPTやGeminiが不得意なこととは?
ChatGPTやGeminiのような一般ユーザーに公開されているLLMはインターネット上のWEBサイトなど公開情報などを元に学習しています。そのため、公開情報が豊富な一般的な内容については対応できますが、公開情報がない(少ない)特定の領域についてChatGPTに質問しても有意義な回答を得ることはできません。
最新の情報やクローズドの環境にしか載っていない情報を得たい場合、現状ではChatGPTの利用は適していません。また、ハルシネーション(幻覚)と呼ばれる、生成AIがもっともらしい嘘(事実とは異なる内容)を返してしまうリスクにも十分な注意が必要です。
生成AI×独自データでつくる実用的なサービス
個人利用においては生成AIによる多少の間違いが起きても許容されるかもしれませんが、ビジネス利用においては大きなトラブルにつながる可能性もあるため、真偽を確認せずに生成AIで得た情報を利用してしまうことは避けなければなりません。
本記事では、インターネットで公開されている情報に加えて、独自のデータ(たとえば社内情報や特定領域の専門知識など)を生成AIの情報源として組み合わせることで、より実用的なサービスを作る方法をご紹介します。
なぜ生成AI×独自データなのか?
LLMは質問を受け取ると学習済みの情報を参照して回答を生成します。そのため、LLMが古い情報しか学習していなければ古い情報を返します。また、正しい情報を返せるだけの十分な学習ができていない場合、もっともらしい嘘を返してしまうこともあります。
既存のLLMが持っていない情報を独自のデータを用いて補うことで、次のメリットが得られます。
- 独自のデータを使用することで、LLMの回答が信頼性のあるものになる
- GPTが学習していない最新の情報や、専門知識、社内の情報を回答に含めることができるようになる
生成AI×独自データの利用例
生成AIに独自データを組み合わせる利用例として、次のようなケースが考えられます。
社内用のチャットボットに「経費として申請できる一回の宿泊代の上限について教えて」と質問すると、社内のマニュアルから該当部分を引用して「宿泊代の上限は一泊当たり1万円です」などの答えを返してくれる。
LLMが単純な検索より優れている点として、前の文脈を理解した上で回答を生成してくれることが挙げられます。先程の宿泊代に関するやりとりの次に「交通費は?」と短文で質問をすると、経費申請の話の続きであることを理解して、経費精算の交通費上限について回答してくれるようになるはずです。

一例として社内マニュアルという独自データを加えることで社員の質問に的確に答える生成AIを紹介しましたが、生成AI×独自データの仕組みは他にもさまざまな活用方法が考えられます。
- 自社製品のマニュアルやFAQなどを使用して、生成AIを活用したカスタマーサポートのサービスをつくる
- 生成AIを業務システムに組み込み、システムに不慣れな人でも使いやすいよう改善する(業務の効率化を図る)
などは実際に企業で導入されている事例もあります。
Slackに質問を書くとAIが答える仕組み
下図は、実際に弊社の社内ポータルサイトのデータ(インターネットには公開されていないクローズド情報)を学習させた生成AIとのやりとりです。
Slackと連携するチャットボットとして作成したので、Slackに特定のメンションをつけた質問を書き込むと、自動的に生成AIが答えてくれます。
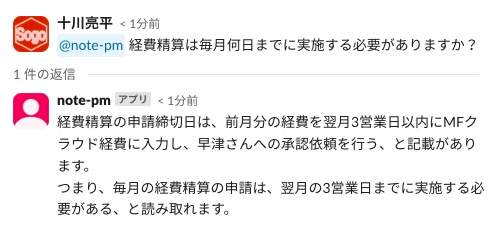
業務上の疑問を普段仕事で使っているチャットなどに書くだけで素早く解決できるようになると、業種を問わず業務の効率化に役立つのではないでしょうか。
生成AIに独自データを使用する仕組み
ここからは少し専門的な「生成AI×独自データ」の仕組みや作り方の話に進みます。
膨大な情報を学習済みのLLMに独自のデータを情報源として加えて使用するには、一般的に検索拡張生成 (RAG: Retrieval Augmented Generation)という手法を用います。
RAGは下図のように、まず独自のデータを検索し、検索結果を元にしたプロンプトをLLMに渡すという仕組みで動きます。このフローにより独自のデータを使った自然言語による結果を返すことができます。
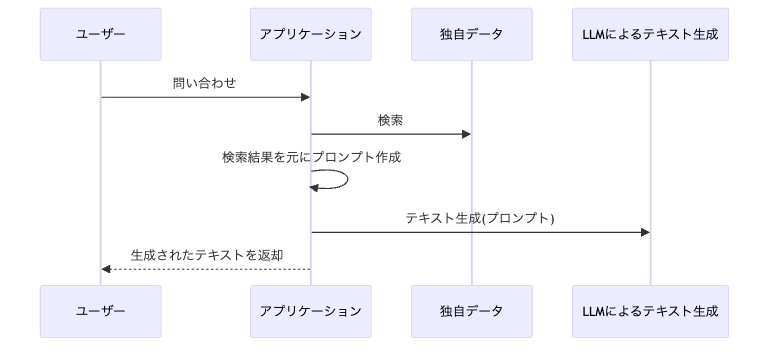
もう少し詳しく説明すると次の流れで精度の高い回答を実現します
1.ユーザーがアプリに質問(問い合わせ)を入力
2.ユーザーの質問に従い、アプリはまず独自データに対して検索を行う
3.2の検索結果を元にアプリがプロンプト(対話形式のシステムにおいてシステムへの命令を伝える指示文)を組み立てる
4.プロンプトが生成AIに送信される
5.生成AIから自然な対話文のかたちで回答が返される
6.アプリがユーザーに回答を提示する
この先はさらに技術的な話にも踏み込みますが、この仕組みを実現する上でポイントとなる「独自データの検索エンジン」と「LLMによるテキスト生成」についてもう少し詳しく説明します。
LLMによるテキスト生成
ChatGPTのような自然なテキスト生成を使いたい場合に、ゼロからLLMを作る必要はありません(もちろん簡単に作れるものでもありません)。
ChatGPTを提供しているOpenAIはAPIを公開しているので、これを利用して独自データと組み合わせたテキスト生成を行うことができます(API(Application Programming Interface)とは簡単にいうとソフトウェアの一部を外部に向けて公開する窓口をつくり、他のソフトウェアと機能を共有できるようにするものです)。
MicrosoftもクラウドサービスAzureの中でAzure OpenAI Serviceを提供しています。いくつかの違いはありますが、基本的にはAzure OpenAI Serviceを使えばChatGPTのAPIと同じようにOpenAIのLLMを外部サービスから使用できます。
Azure OpenAI Service はAzureの他のサービスとの連携が行いやすい、東京リージョンで使用できるなどのメリットもあります。
(Azure OpenAI Serviceで使用できるモデルの一覧はこちらです。モデルごとにどのリージョンで使用できるかも記載されています)
AWSもLLMをAPI経由で利用できる生成AIサービスAmazon Bedrockを提供しています。
RAGに用いる検索エンジン
検索エンジンは独自データの中からユーザーの質問に適切な情報を探してくる際に必要です。こちらもゼロから作る必要はなくクラウドサービスとして提供されているものを活用できます。ただし、使用したい独自データのフォーマットに対応しているかどうかや、LLMとの連携のしやすさを考慮する必要があります。
検索対象のデータとしては例えば次のようなものが考えられます。
- Webサイト(社員しか見ることのできないクローズドのWebサイトや特定領域の専門知識を公開しているWebサイトなど)
- ExcelやWord、PowerPointなどのOfficeファイル
- その他アプリケーションのデータ
これ以外にも多様なフォーマットが考えられるので、独自データとして使いたいものはどんな種類があるかを事前にしっかり確認して、そのフォーマットの中身を読み取れるものを検索エンジンに採用する必要があります。
つづいてRAGに活用できるいくつかの検索サービスをご紹介します。
Amazon Kendra
AWSではAmazon Kendraというサービスが提供されており、これを使うとAmazon S3(クラウドストレージ)に配置したOfficeファイルや、Webサイトをクロールしたデータから簡単に検索インデックスを作成することができます。
コストは高めですが、マネージドサービスなのでメンテナンスを気にしなくて良い点はAmazon Kendraのメリットです。
Azure Cognitive Search
Amazon KendraとAmazon S3の関係と同じように、Azure AI SearchはAzure Blob Storage(クラウドストレージ)にOfficeファイルをアップロードすることで簡単に検索インデックスを作成することができます。
Elasticsearch
AWSやAzureのサービスは有料ですが、OSS(無償で利用でき、プログラムのソースコードが一般に公開されているオープンソースのソフトウェア)では、Elasticsearchなどが使用可能です。
ElasticsearchはWebサイトのクロールや、API経由でのデータの登録などが可能です。プラグインが必要ですがOfficeファイルのインデックス作成も可能です。
なお、AWSにはOpen SearchというElasticsearchをベースとしたマネージドサービスも提供されています。
ここでこれ以上の紹介をするのは控えますが、他にもLLMと連携できるOSSがたくさんあるので、コストや機能を考慮して選択することができます。
Amazon Kendraと、Azure OpenAIを組み合わせた構成
もちろんAWSとAzureの組み合わせによるRAGも考えられます。
以下の図ではAmazon Kendraと、Azure OpenAIを組み合わせたシステム構成を採用しています。
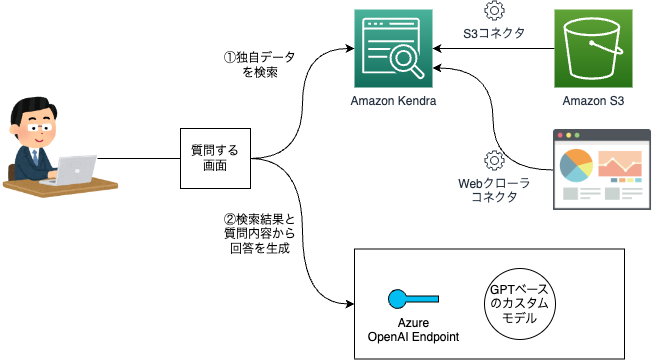
普段はAWSを使っているため独自データの検索はAWS上のデータを対象としたいが、LLMの部分はOpenAIと互換性があるものを使いたいという場合には、このような構成が考えられます。
(2025年4月追記)RAGの実装に欠かせない検索エンジン技術も急速に進化しています。主要なクラウドサービスが提供するRAG向けのマネージドサービスについて2025年4月時点での最新情報を追記します。
AWSはAmazon Bedrockに「Knowledge Base」機能が追加されました。この機能を使うことで自社データをClaudeなどのLLMと連携させたRAGシステムを簡単に構築できます。
Azure Cognitive Searchは「Azure AI Search」に名称変更され、AI機能が大幅に強化されました。OpenAIとの連携も強化されており、少ないコードでRAGシステムの構築が可能です。
Googleの強みである検索技術を活かした「Vertex AI Search」が提供されています。Geminiと連携することで、高度な検索能力を持つRAGシステムの構築を少ない労力で実現できます。
LLMを用いたサービスの開発はNCDCにご相談ください
独自データを使った生成AIサービスのメリットや、システム開発のイメージを掴んでいただけたでしょうか?
NCDCでは、このような生成AIサービスの企画から開発まで一元的にご支援しています。興味のある方はぜひお問い合わせください。