目次
はじめに(AI駆動開発に取り組む方へ」)
この記事では、AI駆動開発の要件定義フェーズにおいて、人とAIが最適な分業を行うためのフレームワークを紹介します。
本フレームワークにより、議事録整理・変更追跡・要件更新といった手間のかかる作業をAIに任せて標準化し、AIがその能力を最大限に発揮し、人間がレビューや意思決定に集中しやすい運用を実現できます。
発注者・開発者という立場を問わず、生成AIを活用してシステム開発プロジェクトの効率化を図りたい方には参考にしていただける内容です。まだ発展途上のフレームワークで改善すべき点もありますが、参考にしていただければ幸いです。
要件定義フェーズでよくある課題
こんな光景に、心当たりはないでしょうか。
システム開発プロジェクトが始まってしばらく経った頃、関係者から「この機能の仕様はどこに書いてありますか?」と問われても誰も回答できず「あの会議で決まったはず…」という曖昧な情報しか出てこない。
つまり、重要な仕様なのに、会議参加者の記憶にしか残っていない。
あるいは、詳細な仕様が確定していないまま放置された要件があり、テスト直前になって各自が思い込みの仕様でつくっていたことが発覚する。
これらは特殊な失敗談ではなく、要件定義の「あるある」といえるのではないでしょうか。重大なトラブルにならない限り表面化しませんが、影ではこうした問題が生じるたびに多くの対応時間が割かれています。
「要件定義の品質は、誰が担当するかで決まる」という現実
システム開発において、要件定義フェーズは全体品質を左右する最重要工程です。にもかかわらず、多くの現場では「議事録の書き方」「要件の言語化」「ドキュメントの構成」「変更管理」などが、熟練担当者の経験と勘に依存したままになっています。
その結果として生まれる課題は、3つに整理できます。
- ドキュメント品質の属人化
議事録の粒度や要件の書き方がばらつくことで、担当者の頭の中にしかない「暗黙知」が生じます。ドキュメントに最低限の「決定事項」だけは書いてあっても「なぜそう決まったか(背景)」が抜け落ちることで、担当者変更時の引継ぎ失敗や、プロジェクト全体の品質不安定化を招きます。 - 不正確な履歴管理
要件定義の過程で仕様変更が生じることは避けられませんが、情報整理の方法が定まっていないと、変更のたびに「どのドキュメントを修正すべきか」「変更がどこに影響するのか」などを手動で総点検する必要があり、修正漏れのリスクも高まります。 - 要件の抜け漏れによる手戻り
上流工程での見落としが開発やテストフェーズになって発覚し、手戻りと追加コストを生むケースは後を絶ちません。プロジェクトの後期で想定外の検討・設計・開発が発生すると、最悪の場合、予算・スケジュールの大幅な見直しに追い込まれます。
「多忙な発注者」というボトルネック
要件定義フェーズでは「発注者側が多忙すぎる」ことによる影響も無視できません。発注者側が打ち合わせの時間を確保できなかったり、開発側からの質問への回答が遅れたりすると、曖昧な要望のまま要件がFIXされたり、例外処理や非機能要件の検討が抜け落ちるリスクが高まります。
また、要件定義書や議事録を、発注者がじっくりレビューする時間を取れないまま承認してしまうと、開発側と発注者側の間に認識のズレが生じたままプロジェクトが進行し、後の工程で手戻りが発生しやすくなります。
なぜ、要件定義は熟練者のスキルに依存してしまうのか?
要件定義とは「何のために・どんな機能を持つシステムを作るか」を明確にし、具体的な仕様として文書にまとめる工程です。発注者の「要求」を、システムの企画や開発に携わる側が「要件」として整理し、発注者と合意形成する作業ともいえます。
- 要求: 発注者やステークホルダがもつ「~したい」という考え
- 要件: 要求をシステムがもつ機能として整理し、ステークホルダと合意したもの
人間同士の対話を中心に合意形成するという作業は構造的に属人化しやすい上に、それを「限られた時間の中で行う」という制約が存在します。ドキュメントを書く側も、確認する側もこれまでに「一切の漏れがなく要件定義を完遂できた」と感じた経験はゼロに近いのではないでしょうか。
AIと人間の協業──高品質で安定した要件定義のためのフレームワーク
「高品質で安定した要件定義を、仕組みとして誰にでも提供できるようにならないか」──この問いから、私たちは生成AIを組み込んだ要件定義フレームワークの構築に着手しました。
ドキュメントの作成・管理で時間を浪費せず、レビューに集中しやすい状態をつくることができれば、発注者側にも、開発者側にも多くのメリットがあります。
フレームワークの核心:「AIに作業を、人間に判断を」
私たちが整備したフレームワークにおける重要な点は、生成AIと人間の役割分担を明確に定義することにあります。
AIが担うのは、ドキュメントの構造化、情報の抽出、IDタグ付けによるトレーサビリティの維持、既存文書の差分分析といった「効率化できる単純作業」です。一方、人間が担うのは、最終意思決定、事実確認とニュアンスのチェック、顧客とのビジョンの合意形成、交渉──つまり「価値を創出する判断業務」です。
| 人間が担う業務 | 生成AIが担う業務 |
|---|---|
| 判断・合意形成・責任を引き受けて価値を創出する業務 ◾️要件・仕様の最終意思決定 ◾️事実確認とニュアンスのチェック ◾️顧客とのビジョンの合意形成・交渉 | 効率化できる単純作業 ◾️議事録などのドキュメントの生成・構造化 ◾️情報の抽出・タグ付け ◾️IDによるトレーサビリティの維持 ◾️既存文書の差分管理 |
生成AIはあくまで「優秀なドキュメントアシスタント」であり、判断と責任は常に人間が持ちます。「AIに全てを任せない」という大原則がフレームワーク全体を貫いています。
前置きが長くなりましたが、次の章から本フレームワークの具体的な内容をご紹介します。
議事録からドキュメントやGitHubイシューを自動生成
まず、前提として、本フレームワーク自体は特定のサービスに依存しません。
2026年5月現在、NCDCではドキュメント管理にはGitHub、ドキュメント生成AIにはGitHub Copilotを利用しています。
Gitによるバージョン管理とAIエージェントが連携する環境を活用することで、Copilotが生成したドキュメントが自動的にフォルダに保存され、変更箇所も明示されるため、人間のレビューの高速化と精度向上が可能です。
なお、Gitホスティング(GitLab、Bitbucket等)とAIエージェント(Claude Code、Cursor等)の組み合わせでも同様に実現可能です。
GeminiやChatGPTなどでもドキュメント生成は可能ですが、変更・差分確認が煩雑になりがちな点が課題です。生成AIのハルシネーション(意図しない要件の書き換えや追加)を検知するためにAIが変更した箇所を「差分」として明確に可視化できるツールとして、ドキュメント生成AIにはGitHub Copilotを採用しています。
GitHubのフォルダ構成は以下のとおりです。
.
├── .ai/
│ ├── agents/
│ └── skills/
├── docs/
│ └── templates/
│ └── outputs/
| フォルダ | 役割 |
|---|---|
| ai/agents/ | 特定の役割・専門性を与えるプロンプトファイルを置く |
| ai/skills/ | agentsが行う具体的な作業内容を示すファイルを置く(業務マニュアル置き場) |
| docs/templates/ | 出力ドキュメントのテンプレートを置く |
| docs/outputs/ | 生成されたドキュメントの出力先 |
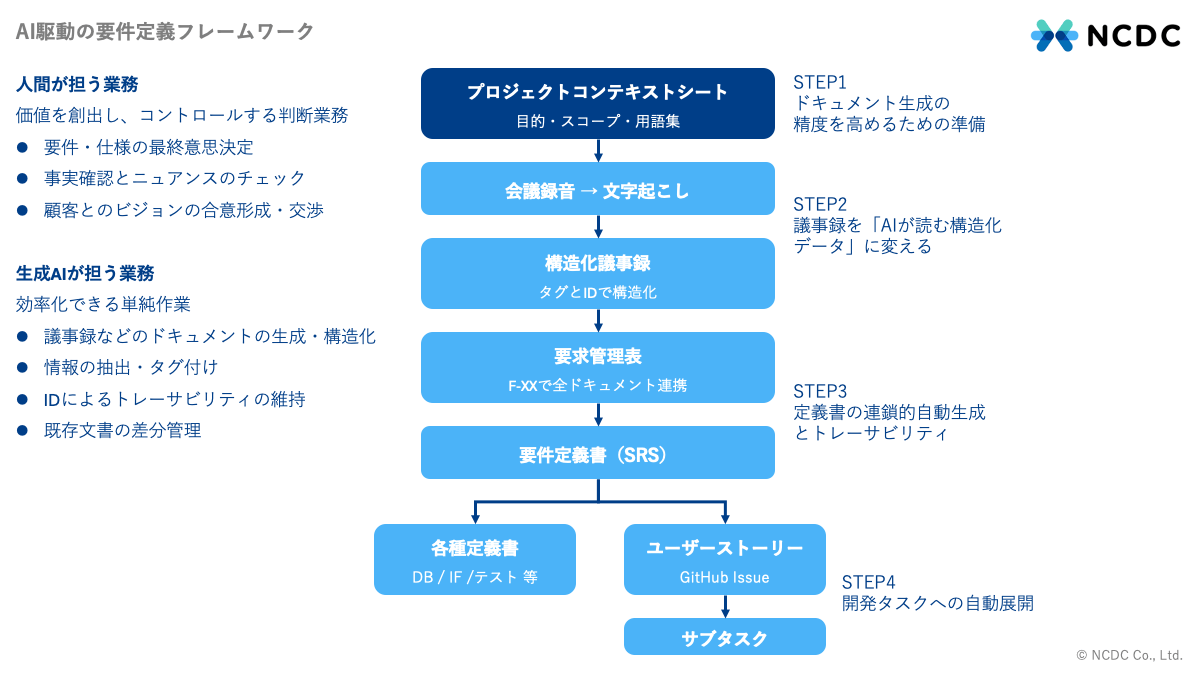
議事録からドキュメントやGitHubイシューを自動生成するまでのプロセスは4ステップで構成されています。
- STEP 1:ドキュメント生成の精度を高めるための準備(プロジェクトコンテキストの設定)
- STEP 2:議事録を「AIが読む構造化データ」に変える(構造化議事録の作成)
- STEP 3:定義書の連鎖的自動生成とトレーサビリティ(構造化議事録から各種定義書を作成)
- STEP 4:開発タスクへの自動展開(GitHub Issueへの展開 )
各STEPで付与される要求ID(F-XX)が全ドキュメントを貫くことで、上流から下流までのトレーサビリティが自動的に担保されます。
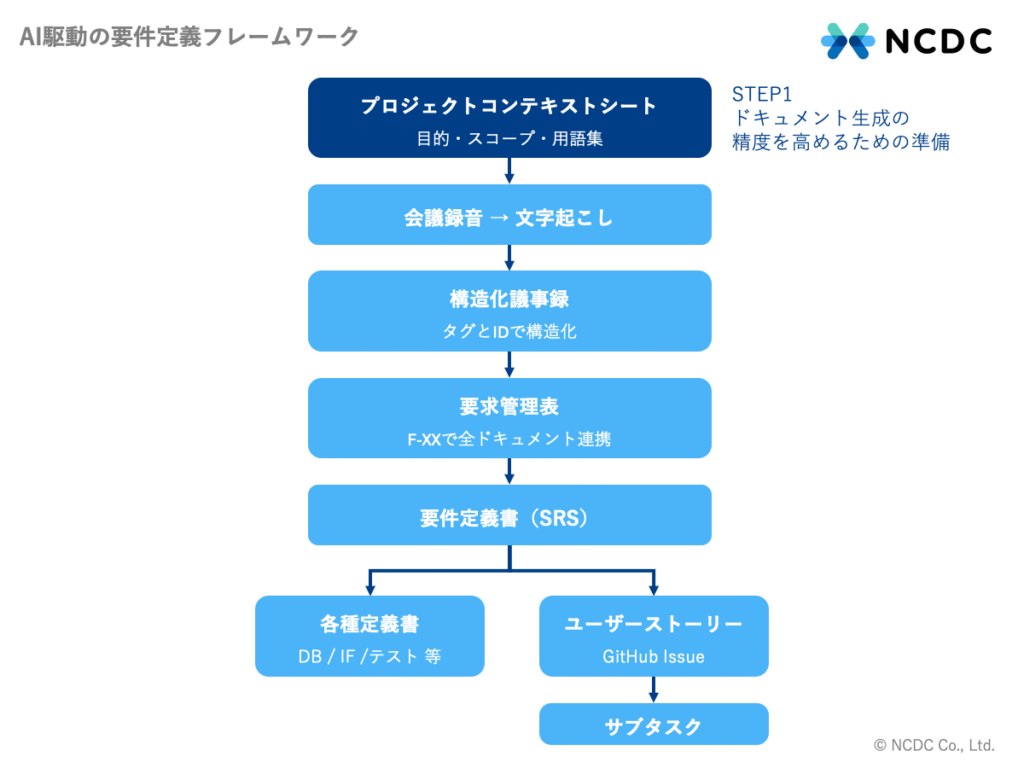
STEP 1:ドキュメント生成の精度を高めるための準備
このフレームワークでは、AIに対してプロジェクト固有の情報を事前にまとめて渡すためのドキュメントを「プロジェクトコンテキストシート」と呼んでいます。インセプションデッキなど既存のPMフレームワークで使われている一般的な用語ではなく、本フレームワーク独自の概念です。
すべての起点となるのがこのシートです。AIにプロジェクトの目的・背景・スコープ・用語などを事前にインプットすることで、後続のドキュメント生成の精度と一貫性を高めます。ここを丁寧に整備しておくことで、AIが生成する議事録・要件定義書・定義書類のすべてが、プロジェクト固有の文脈を踏まえた内容になります。
逆に、この準備を省くと後続のすべてのドキュメントが文脈からズレた汎用的な内容になりやすく、レビューコストが増加する原因にもなります。次のSTEP2以降の品質を左右する、最も重要な準備工程です。
プロジェクトコンテキストシートには、以下の情報を整理してMarkdownで作成します。
- プロジェクト概要・目的:なぜこのプロジェクトをやるのか?
- 主要なステークホルダー:誰が関わっているのか?
- 対象利用者(ペルソナ):誰のために作るのか?
- システム化の範囲(スコープ):何を作り、何を作らないか?
- 制約条件・前提条件:守るべきルールは何か?
- 用語集:プロジェクト固有の言葉の定義は?
本フレームワークの「プロジェクトコンテキストシート」は、「AIが一貫したドキュメントを生成するために必要な最低限の文脈情報をインプットする」ことに特化した、AIを主な読み手として設計したドキュメントです。そのため、AIへの指示に直結する6項目に絞り込んでいます。
既存フレームワークとの名称の違いは、この「読み手がAIである」という設計思想の違いを明示するためのものです。
従来のシステム開発手法でも類似の情報を扱うものとして「プロジェクト憲章」や「インセプションデッキ」等がありますが、これらはステークホルダーへの承認取得やチームの合意形成を目的とした「人間が読むための文書」です。AIにとっては不要な情報も多く含まれるため、本フレームワークでは採用しません。
用語集(いわゆるユビキタス言語)は、従来のシステム開発手法でも整備の重要性がよく語られるものの、更新が追いつかず陳腐化しがちという課題を多くの現場が抱えています。
本フレームワークでは、議事録から新たな用語をAIが自動抽出して用語集に反映する運用を組み込んでいるため、メンテナンスの手間を抑えながら用語集を生きたドキュメントとして維持できます。用語が統一されることで、AIが同一概念を異なる表現で出力する事態も防げるため、後続ドキュメント全体の一貫性向上にもつながります。
作成後、AIに対して「添付のプロジェクトコンテキストシートを読み込んでください」と指示してコンテキストを共有した上で、同じ会話の中でSTEP2以降の作業を進めます。
STEP 2:議事録を「AIが読む構造化データ」に変える
まず、前述の「準備」を完遂させることが重要です。その後に、人が会議で要件を確認し、議事録や要件定義書を作成する実践フェーズに入ります。
ここで、一つ問い直してほしいことがあります。
「議事録は、誰のために書くものか?」
おそらく多くの人は「人間が読み返すため」と答えるでしょう。後から参照したり、引き継ぎ資料として使ったり、「あのとき決まったこと」を証明するための文書──そう捉えている方がほとんどのはずです。
しかし本フレームワークでは、その前提をひっくり返します。
議事録は、AIが処理するための構造化データソースである。
人間が読む文書であれば、多少の文体のゆらぎや情報の粒度のばらつきがあっても「なんとなく伝わる」で済みます。しかしAIが後続ドキュメントを生成するためのインプットとして使う場合、議事録の構造と情報密度が、そのままドキュメント品質に直結します。
「よい議事録=人間にわかりやすい記録」から「よい議事録=AIが正確に処理できる構造化データ」へ──この発想の転換が、本フレームワークの核心のひとつです。
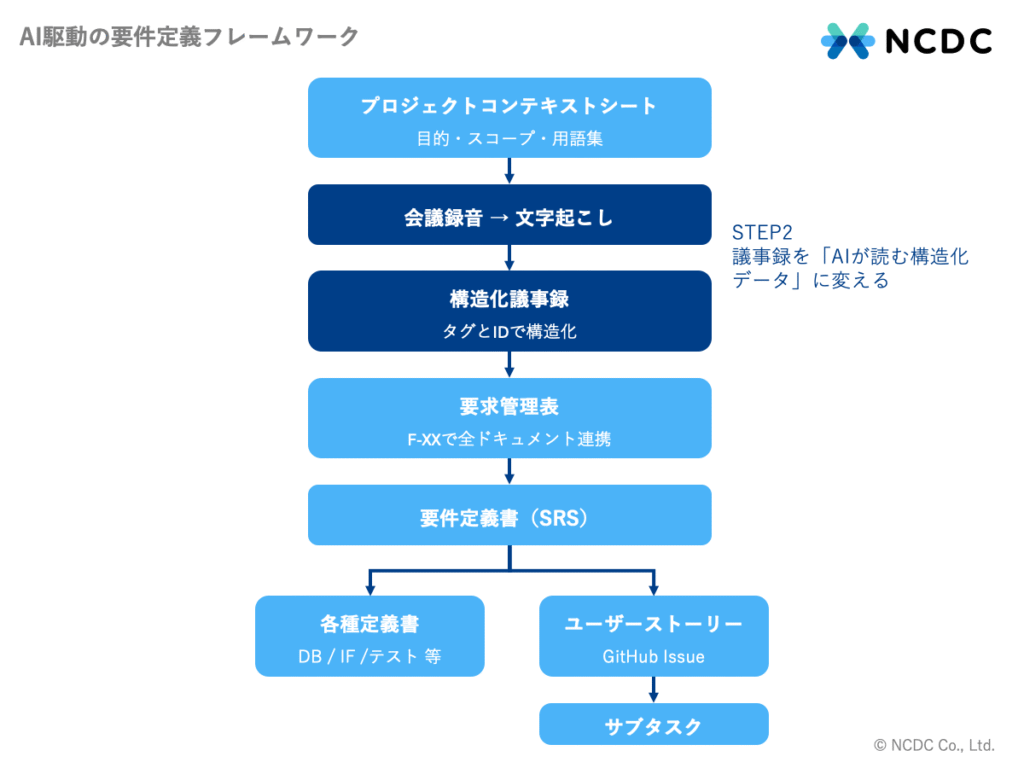
具体的には、まず会議の録音・録画データから文字起こしを行い「生の議事録」を用意します。次に、この文字起こしをインプットとして議事録作成用プロンプトを用い、AIが「ただの議事録」を「AIが処理するための構造化された議事録」へと作り変えます。
この変換においてAIが行うのは、発言内容の整理・分類・タグ付けであり、発言されていない情報を推測・補完することではありません。プロンプトに「文字起こしの内容のみを使用し、記載されていない情報を追加・補完しないこと」といった制約を明示することで、AIによる意図しない情報の付け足しを防ぐことが重要です。生成後は元の文字起こしと突き合わせてレビューし、AIが勝手に追記した箇所がないかを確認する習慣をつけてください。
この構造化議事録が後続ドキュメントの唯一のインプットになるため、レビューは入念に行ってください。会議で議論されたにもかかわらず議事録に入っていない情報は、以降のドキュメントに一切反映されないためです。
構造化議事録は、以下の4つのセクションで構成されます。
- 会議の基本情報:日時・場所・プロジェクト名・参加者
- 会議の結果サマリ:決定事項(合意内容)と保留事項・宿題(次回アクション)
- 発言内容(詳細):発言者と内容を整理した本文
- 要求管理表・要件定義AI用インデックス:抽出された要求リスト、データ項目リスト、外部連携リスト、未解決課題リスト
このうち特に重要なのが「要求管理表・要件定義AI用インデックス」です。ここに抽出された情報が、後続の要求管理表・要件定義書の直接のインプットとなります。
構造化議事録では、以下のタグ体系を用います。
| タグ | 意味 |
|---|---|
| [REQ-NEW] | 新規要求に付与 |
| [REQ-CHG] | 既存要求への仕様変更に付与 |
| [DATA] | データ項目や属性に関する発言に付与 |
| [IF] | 外部システム・サービスとの連携に関する発言に付与 |
| [Q] | 未確定仕様や追加確認が必要な事項に付与 |
[REQ-XXX]タグには[F-XX]というIDが自動的に振られ、以降に作成する「要求管理表」「要件定義書」などすべてのドキュメントで同じIDで仕様を管理します。これにより、全ドキュメントのトレーサビリティが自動的に担保されます。
なお、2回目以降の会議では、既存の要求管理表の最新版を議事録作成プロンプトにインプットとして含めます。これにより、AIが「新規要求(REQ-NEW)」と「既存要求への変更(REQ-CHG: F-XX)」を自動的に判別し、適切なタグとIDを付与できるようになります。
なお、このフレームワークはAIへのインプットの質に依存します。会議での発言が曖昧なままだと、AIが補完・推測を行ってしまい、意図しない要件がドキュメントに混入するリスクがあります。以下は最低限整備を推奨する会議ルールです。
曖昧な指示語を使わない
「あれをそっちの仕様に合わせてください」のような発言は、AIが指示対象を判断できません。AIは文脈から推測して要件を生成しようとするため、実際には議論されていない仕様がドキュメントに混入するリスクがあります。また推測ができない場合は[Q]タグを付けて保留扱いにしますが、その場合も後続のレビューコストが増加します。「ユーザー登録画面のバリデーション仕様を、パスワードポリシー定義書のXX項に合わせてください」のように、主語と対象を明確に発言することが重要です。
結論ファーストで話す
A案・B案を長々と検討したのち「まあA案でいいんじゃないですかね」のような曖昧な締め方をすると、AIはこれを決定事項([REQ-NEW])として扱うべきか、未確定の保留事項([Q])として扱うべきか判断できません。決定事項と誤認識した場合は根拠のない要件がドキュメントに記録され、後の工程で混乱を招きます。「A案を採用します。理由はコスト面での優位性です」のように、結論と根拠を先に述べることで、AIが正確にタグ付けできるようになります。
人によって解釈が異なるような曖昧さを排除することはAI駆動で要件定義を行うかどうかに関わらず重要なポイントです。そのため、発注者側の参加者も含めて、こうした会議のルールを関係者に共有して、全員で会議の質の向上に取り組むことも大切です。
議事録の構造化精度は会議全体の発言品質に依存するため、一部の参加者だけが意識しても効果は半減します。
こうした地道な整備がフレームワーク全体の品質を底上げします。
STEP 3:定義書の連鎖的自動生成とトレーサビリティ
構造化議事録を起点に、要求管理表・業務フロー図・要件定義書(SRS)・データ定義書・インターフェース定義書・テスト仕様書・WBS(Work Breakdown Structure)までを連鎖的に生成させます。
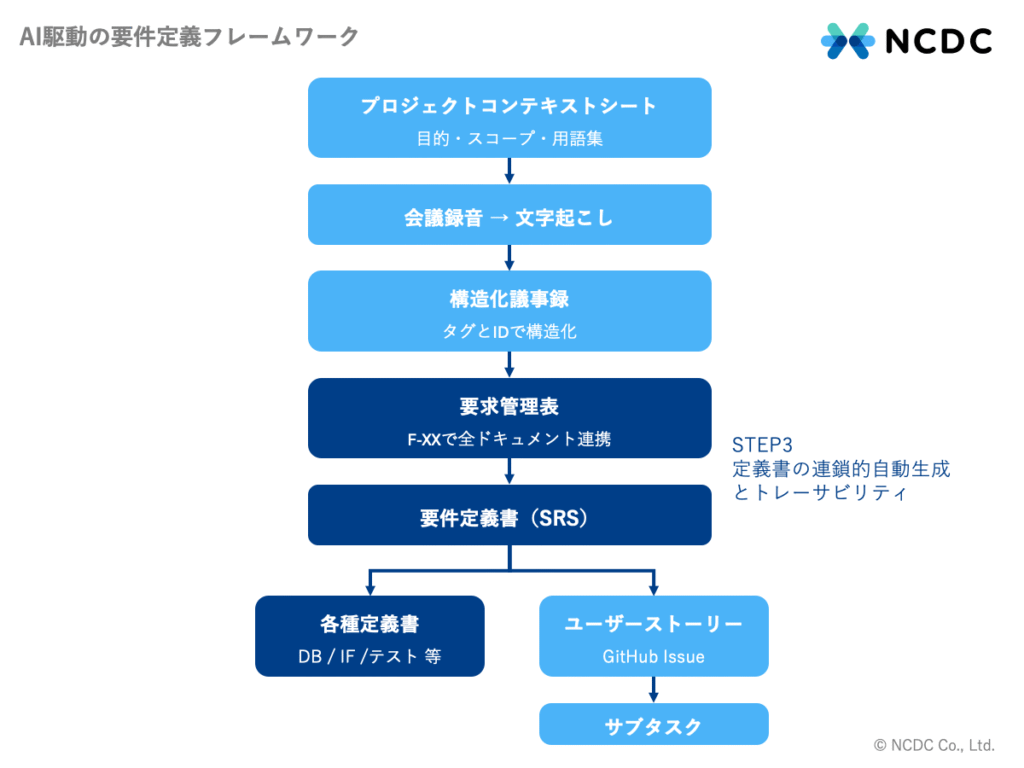
構造化議事録から最初に生成するのが要求管理表です。ビジネス要求をID・優先度・要求内容・関連業務ステップなどの項目で一元管理し、以降のすべてのドキュメントでこのIDが引き継がれます。要求管理表のIDが、フレームワーク全体のトレーサビリティの核です。
各ドキュメント間でIDが引き継がれるため、「どの会議でどの要件が決まったか」を自動的にトレースできる状態が実現します。これが従来のアプローチとの最大の違いです。仕様変更が発生しても、IDをキーに影響範囲を即座に特定でき、更新対象のドキュメントを絞り込むことができます。
生成順序としては、要求管理表 → 要件定義書の順を推奨します。要件定義とは本来、顧客の「要求(何をしたいか)」を受け取り、それをシステムで実現すべき「要件(何を作るか)」に落とし込むプロセスです。要求管理表がその橋渡し役であり、議事録から抽出した顧客要求をID付きで一元管理します。この要求管理表が固まった状態で要件定義書を生成することで、要求と要件の対応関係が明確になり、IDの一貫性も保たれます。また、要求管理表が中間チェックポイントとして機能するため、議事録からの情報抽出の誤りを要件定義書の生成前に検出できる点でも有効です。その他のドキュメントは要件定義書がある程度固まってから作成するほうが、更新管理コストを抑えられます。
なお、AIが意図せず既存のFIX済み箇所を書き換えたり削除するケースがあるため、GitHubの差分管理機能を使い、AIが修正した箇所を明示して目視確認することでこの問題に対処します。この差分確認は必ず人の手で行う必要があります。
業務フロー図やWBSについては、現時点でAIの生成精度が高くないため、叩き台として出力し人の手で修正する運用を前提に考えておくことを推奨します(詳細は後述します)。
仕様変更が発生した場合は、変更内容を[REQ-CHG]タグで抽出し、AIに既存ドキュメントへの影響範囲を分析させます。影響範囲が特定できたら、PMが工数・スケジュールへの影響を評価し、承認を得てから要求管理表→要件定義書→テスト仕様書の順に更新します。IDによるトレーサビリティがあるため、どのドキュメントのどの箇所を更新すべきかが即座に判断できます。
STEP 4:開発タスクへの自動展開
要件定義書が完成したら、GitHubのIssueとしてユーザーストーリーを生成します。
ユーザーストーリーとは、「〇〇機能によって▲▲操作ができる」など、機能要求をユーザー目線で記述したものです。アジャイル開発において開発タスクの起点となる概念です。
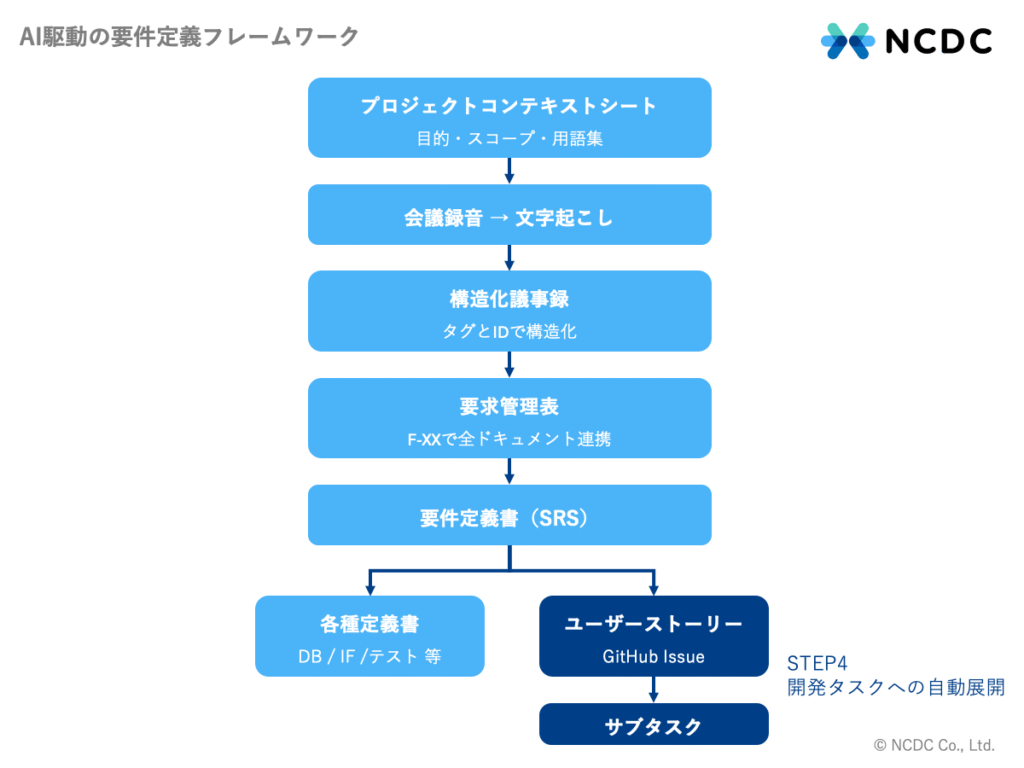
本フレームワークでは、要件定義書の機能要件の大項目ごとにユーザーストーリーをIssueとして起票し、その配下に開発タスクを紐付けます。各ストーリーには、対応する要件ID(F-XX)を明記し、開発タスクもこれを継承します。これにより、要件定義書→ストーリー→開発タスクまで一貫したトレーサビリティが維持されます。GitHub Actionsを活用することで、開発タスクも自動起票できます。
会社によってユーザーストーリーや開発タスクの記載フォーマットが異なると思いますので、プロンプト内の出力テンプレートを調整してください。これにより、要件定義フェーズから実装フェーズへのバトンが、シームレスにつながる仕組みです。加えてすべてのドキュメントがMarkdownとGitで管理されるため、バージョン管理・変更追跡も自動化されています。
従来型の要件定義プロセスとの比較
ほぼすべてのプロセスを人が行う従来のやり方とAI駆動型の本フレームワークを比較すると次のようになります。
| 観点 | 従来型 | AI駆動型(本フレームワーク) |
|---|---|---|
| 議事録作成 | 手動記述 | AI自動生成+人間レビュー |
| ドキュメント生成 | 手動作成 | AI自動生成+人間レビュー |
| ドキュメント品質 | 個人スキルに依存する | 正しいプロセスで行えば標準化される |
| トレーサビリティ | 手動管理(漏れやすい) | ID自動付与・自動追跡 |
| 変更対応 | 複数ドキュメント手動更新 | 差分管理で自動検出 |
フレームワーク活用のポイントと適用限界
本フレームワークを適用することで、冒頭で挙げた要件定義の3つの課題は、以下のように解決されます。
| 3つの課題 | AI活用のポイント | 人間が得るメリット |
|---|---|---|
| ドキュメント品質の属人化 | 議事録の自動構造化と、Markdownテンプレートによる出力形式の標準化。 | 議事録作成や書式の調整に要していたリソースを、例外パターンの検討や仕様のレビューに集中できる。 |
| 不正確な履歴管理 | 要求と各ドキュメント、開発タスク(GitHub Issue)へのID(F-XX)自動付与・継承。 | 仕様変更時の影響範囲を機械的に即座に特定でき、更新漏れや調査のブラックボックス化を防げる。 |
| 要件の抜け漏れと手戻り | 会議の文字起こしデータに基づく一元的な情報抽出と、AIによる抜け漏れレビュー。 | 網羅性の担保はAIに任せ、人間は「要求のニュアンスの確認」や「発注者との合意形成」に注力できる。 |
続いて、このフレームワークを数人月規模の要件定義・開発プロジェクトで実際に運用してみた効果と注意点を整理しました。
工数削減効果
まだ数少ないプロジェクトでの試験運用のため、プロジェクトの特性の影響を受けていたり、手探りで進めているため多少の上振れはありますが、ドキュメントにかかる時間を比較すると、下記の効果がありました。
- 議事録作成時間の削減率:約80%
- 要件定義書作成工数の削減率:約50%
先述のとおり、このフレームワークはAIにすべてを任せるのではなく「作業はAIに任せ、人は価値の創出やコントロールを担う判断業務に注力する」ということが目的です。
したがって、このドキュメント作成時間の削減が、単純にすべてプロジェクト期間やコストの削減に直結するわけではありません。しかし、効率化した分の時間をドキュメントの精緻化や仕様の検討・意思決定のための時間に充てることで、確実に品質向上に繋がっています。
効果的に活用するためのポイント
プロジェクトコンテキストシートの精度が、後続ドキュメント全体の品質を高める
STEP1にも記載しましたが、プロジェクトコンテキストシートの出来が全体の成否を左右します。プロジェクトの目的・スコープ・用語集などを丁寧に整備して、はじめにAIに正しく伝えることがとても重要です。この初期投資を怠ると、プロジェクト固有の文脈に沿ったドキュメントが生成されず、レビューのコストが増大する上に、後工程全体の品質にも影響します。
継続更新と差分確認がドキュメントの品質を担保する
AIに生成させたドキュメントを常に最新の状態に保つには、打ち合わせのたびに議事録を都度取り込み、ドキュメントを更新させる習慣が不可欠です。ある程度溜まってから一気に更新をかけると、AIが決定の時系列を無視したドキュメントの更新をかけてしまいます。
さらに、GitHubなどのバージョン管理機能を活用することで、AIの更新部分を人の目でチェックし、AIによる意図しない要件の追加・書き換えを検出できます。差分確認の習慣がAI活用の品質を支えます。
テスト仕様書の早期作成が、要件品質を検証することになる
要件が固まった段階でテスト仕様書の叩き台を作成し、チームで確認することで、要件定義の抜け漏れや解釈のずれを上流工程で発見できます。なお、AIによるテスト仕様書は正常系のカバレッジはある程度確保できるものの、異常系・境界値のケース抽出が不十分になりがちです。要件確定時点でのテスト仕様書の叩き台を「要件の確認ツール」として利用し、開発が進む中で例外やエッジケースを網羅するようにブラッシュアップしていく運用が有効です。
適用限界と人間の関わり方の整理
後続の下流ドキュメントはAI生成に依存しすぎない
STEP3にも記載しましたが、業務フロー図やWBS、データ定義書は現時点ではAIの苦手分野です。これらのドキュメントもAIが叩き台を高速に出力できる点では有効ですが、必ず人間が修正・補完する前提で利用することを推奨します。
業務フロー図は、単純な直線的フローであればMermaid記法(テキストを書くだけで、フローチャートや図を自動で作成できる仕組み)での出力が可能ですが、条件分岐や例外フローが複雑になると構造が崩れやすくなります。「実務レベルの複雑なフロー」を書かせると構造が破綻してしまうケースが多くありました。
WBSは、要件をもとにタスクの洗い出しと階層構造の生成はできるものの、チームのスキルセット・体制・実績工数を考慮した現実的な工数見積もりは生成できません。
データ定義書についても、表記揺れに起因して同じ項目が二重に生成されるなど、文脈に依存する判断によりAIが誤るケースが見られました。
ドキュメント数が増えると整合性の維持が難しくなる
管理対象のドキュメントの量が多くなるほど、AIが管理するタスクが複雑になり、精度や実行時間の面で限界が生じます。管理するドキュメントの数や粒度は、プロジェクトの規模に応じて調整することが重要です。
非機能要件の調整はプロジェクトコンテキストに基づいて人間が主導する
非機能要件は、プロジェクト固有の背景や優先度に基づくため、AIによる生成精度が安定しません。AIの出力を参照しつつ、最終的には人間がプロジェクトのコンテキストに基づいて設計・調整する領域として位置付けてください。
多忙な発注者の負担を減らす「差分レビュー」
このフレームワークは「開発者」のためだけのものではありません。冒頭で触れた「多忙な発注者がレビュー時間を取れない」という課題の解決にもつながります。
発注者に毎回、大量の議事録や要件定義書全体を読み直してもらうのは現実的ではありませんが、このフレームワークであれば「差分」だけを確認してもらう運用が容易になります。
発注者は、会議のたびに更新されたピンポイントの変更点(新規要求や変更要件)だけを見ればよいため、確認の負担が大きく減ります。結果として、ドキュメントを読み込む「作業」に追われることなく、「この要件で本当にビジネスゴールを達成できるか」という本質的な合意形成に時間を使えるようになります。
AI駆動の要件定義フレームワークを機能させる原則
実践を通じて分かったのは、AIの精度以上に、人間のレビューと運用設計が品質を左右するということです。「誰でも高い品質を保てるようにする」ことが目標ですが、「人が何もしなくともAIが勝手にやってくれる」という状態を目指すものではありません。
人間によるレビューの重要性
このフレームワークで生成AIが作るドキュメントはあくまで「叩き台」であり、人間のレビューと修正が不可欠です。
ただし、これは「最終的にレビュー担当者の力量が品質を決める」という意味ではありません。本フレームワークは、ドキュメント作成だけでなくレビュー作業そのものも以下の仕組みで標準化しています。
- 構造化議事録のタグ体系([REQ-NEW] / [REQ-CHG] / [Q] など)により、確認すべき観点が明示される
- 要求IDによるトレーサビリティにより、変更影響範囲の見落としを機械的に防ぐ
- GitHubの差分管理により、AIの変更箇所が可視化され、目視確認の対象が絞り込まれる
つまりレビュー担当者は「白紙からドキュメント全体を評価する」のではなく、「決められた観点に沿って、明示された差分を確認する」作業に集中できます。これにより、「ゼロから書く属人性」を「決められた観点で確認する属人性」に置き換え、誰が担当しても再現性を担保しやすくしています。
最終的な品質判断は人間に委ねられますが、本フレームワークは「人間のスキルを不要にする」ものではなく、「人間が注力すべきポイントを明確化し、属人性を最小化する仕組み」として位置づけています。
未決定事項の明確な管理
AIによるハルシネーションに振り回されないために、「未決定事項」と「決定事項」はいつでも明確に確認できるようにすることが重要です。
このフレームワークは「AIに任せて完成させる」ものではなく、「AIを使って高速にドラフトを作り、人間が確認・修正する」協働モデルです。引き続き、弊社内で継続的に改善・検証を進めています。
まとめ:「個人の力量」から「チームの仕組み」へ
要件定義の品質を安定させるための本質は、「優秀な個人に頼る」ことではなく、「誰がやっても一定水準を担保できるプロセスを設計する」ことにあります。
本稿で紹介したフレームワークは、その考え方を生成AIで実現しようとする試みです。プロジェクトコンテキストの整備、議事録の構造化、トレーサブルなドキュメント連鎖生成、そして開発タスクへの自動展開──この4ステップが一気通貫でつながることで、品質を安定させる基盤が整います。
一方で、本フレームワークの実践を通じて得た最大の気づきは、「AIの精度向上と業務プロセス設計の両方が重要である」ということです。
会議での発言の質、レビューの精度、差分確認の徹底──AIを活かせるかどうかは、結局のところチームの運用習慣に依存します。
熟練者のスキルへの依存、ドキュメント品質のばらつきという要件定義の長年の課題は、ツールを変えるだけでは解決しません。しかし、適切なプロセス設計と生成AIの組み合わせによって、確実に改善できる問題でもあります。弊社でもまだ改善途上ですが、同じ課題を抱えるプロジェクトチームにとって、本稿が一つの実践的な参考になれば幸いです。
このフレームワークが提供するのは、AIを活かすためのプロセス設計そのものです。NCDCでは、このフレームワークを用いた要件定義〜プロジェクトマネジメント手法の導入を支援することが可能です。要件定義にお困りのプロジェクトマネージャーの方、システム内製化を考えていて実践的なノウハウを探している方はぜひ一度ご相談ください!