目次
「生成AIを導入したはいいが、毎月の請求額が想定より高くなってしまった」「使えば使うほどコストが膨らんでいく気がする」生成AIを業務で活用する企業の担当者から、こうした声がよく聞かれます。
弊社NCDCでも、法人向けAIエージェント「BizAigent」を開発・提供する中で、このコスト問題と向き合ってきました。本稿では、本番運用に耐えうるコスト効率を実現するまでの過程で得た知見を共有します。
生成AIのコスト最適化には、モデル選定、プロンプト設計などさまざまな打ち手がありますが、その中でも、運用フェーズで特に効果を発揮するのが「キャッシュ」の活用です。
ただし、LLM(大規模言語モデル:生成AIのうち特にテキスト処理に特化したモデル)の世界で「キャッシュ」と一括りに語られているものは、実際には性質の違うものが複数あり、これを混同したまま設計を進めると効果を得たい箇所で機能しないという事態が起きます。
なお、本題に入る前に用語の整理をしておきます。
本稿では、「プロンプト」という言葉をLLMに送る入力全体を指す広い意味で使います。具体的には、ユーザーが入力した質問だけでなく、システムプロンプト、過去の会話履歴、参照文書、ツール定義などすべてを含みます。厳密にはこれらを「コンテキスト」と呼ぶ場合もありますが、用語を増やすと話が複雑になるため、本稿では区別しません。
なぜ生成AIのコストは膨らみやすいのか
課金の仕組み:トークン・回数・モデル差
生成AIの利用料は「LLMに送った文字数+LLMから返ってきた文字数」で決まります。
正確には、文字や単語を「トークン」という単位に区切って数えます。トークン数の目安は以下の通りです。
- 日本語:およそ1文字=1〜3トークン
- 英語:1単語=1トークン程度
コスト構造を整理すると、料金はおおむね次の式で決まります。
料金=(入力トークン数×入力単価+出力トークン数×出力単価)×呼び出し回数
従来のシステムとの構造的違い
生成AI呼び出しのコスト構造は、従来のシステムとは根本的に異なります。
| 項目 | 従来のWebアプリ | 生成AIアプリ |
|---|---|---|
| 1リクエストの処理コスト | ほぼゼロ(CPU時間のみ) | 数円〜数十円 |
| レスポンス時間 | 数十ミリ秒 | 数秒〜十数秒 |
| 主な変動要因 | リクエスト数 | トークン量×モデル単価 |
従来のWebアプリも、もちろんインフラコストはかかります。ただし1リクエストあたりの単価が桁違いに小さく、トラフィックが増えても比例的に積み上がるだけでした。一方、生成AIは1リクエストあたりのコストが大きく、しかも入力データのサイズによって1桁以上変動するという構造になっています。同じユーザー数でも、扱うデータの設計次第で月額コストが何倍も変わります。
入力トークンの「肥大化」が起きる構造
特に問題になるのが「入力トークンの肥大化」です。
生成AIアプリでは、ユーザーの質問本文以外にも毎回さまざまな情報を一緒にLLMに送る必要があります。
- システムプロンプト:生成AIの役割や応答ルールを定義する指示文(毎回固定)
- ツール定義:LLM単体ではメールを送ったり社内システムを操作したりはできないため、「使える外部ツール」の一覧と使い方を毎回LLMに教える必要がある(毎回固定)
- 過去の会話履歴:文脈を保つためにセッション内で積み上がる履歴
- RAGで取得した社内文書:外部の文書データベースから関連情報を検索し、それをもとに回答の精度を高める技術(RAG)を用いると、その情報は質問ごとに動的に取得されるため、数千〜数万トークンに及ぶことも
ユーザーが質問本文に「こんにちは」と5文字打っただけでも、その裏では大量のデータがLLMに送られている。
そんな状況が、業務活用される生成AIアプリでは起きがちです。
生成AIで押さえるべき「セマンティックキャッシュ」と「プロンプトキャッシュ」
「キャッシュ」とは一般に、「一度作った結果を保存しておき、次回以降に再利用する仕組み」のことです。生成AIのコスト削減でも、このキャッシュが有効です。
生成AIの周辺にも複数のキャッシュ機構が存在します。
その中でも、生成AIを業務活用するうえでコスト最適化の中心となるのが、次の2つです。
- セマンティックキャッシュ(意味的キャッシュ)
- プロンプトキャッシュ
2つのキャッシュは「働く層」が違う
この2つは、名前は似ていても働く場所も効果も使いどころも全く違います。
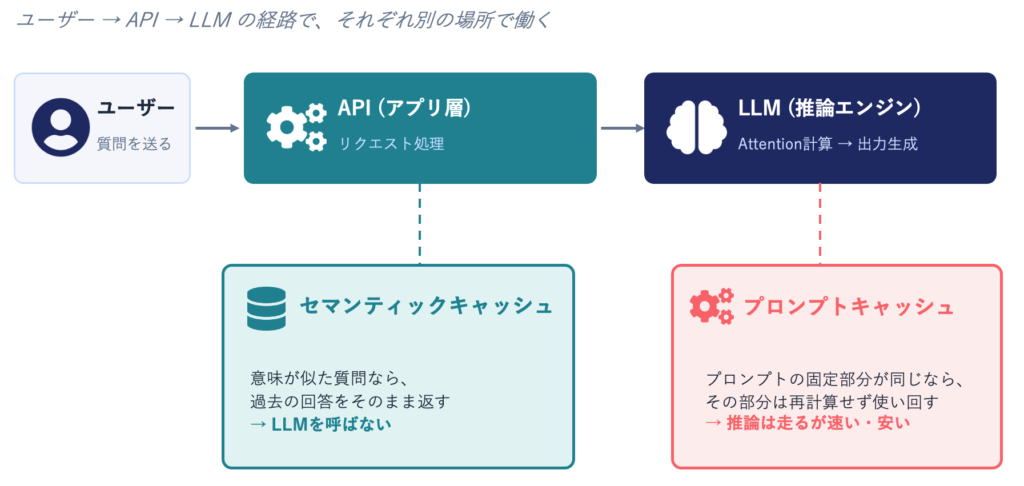
ユーザーの質問がLLMに届くまでの経路を分解すると、以下のようになります。
セマンティックキャッシュ:そもそもLLMを呼び出さない
セマンティックキャッシュは、LLMへの問い合わせを行う手前の段階で動きます。ユーザーから質問が来たら、過去に答えたことのある質問群と「意味の近さ」を比較し、十分に似た質問が見つかれば、過去の回答をそのまま返却します。LLMへの問い合わせは発生しません。
「東京の人口は?」「東京って何人住んでるの?」「Tokyoのpopulation教えて」これらは表現が違っても意味は同じです。一度答えを出しておけば、次回以降はLLMを呼び出さずに即座に同じ答えを得られます。
削減されるのは「LLMの呼び出しそのもの」です。
プロンプトキャッシュ:LLM内部の計算を使い回す
一方、プロンプトキャッシュはLLMの内部で動きます。
LLMは本来、入力された全トークンを毎回ゼロから解釈(専門用語で言うAttention計算)します。プロンプトキャッシュは、プロンプトの中で同じ部分の計算結果を保存しておき、次回以降そこを再計算せずに使い回す仕組みです。
リクエスト自体はLLMに届きます。出力も毎回新しく生成されます。削減されるのは「入力解釈にかかる計算コスト」です。
それでもインパクトは大きく、AnthropicClaudeのプロンプトキャッシュでは、キャッシュヒット時の入力トークン課金が通常の10%程度まで下がります。また、レスポンス時間も大幅に短縮されます。
セマンティックキャッシュとプロンプトキャッシュの違い まとめ
| 観点 | セマンティックキャッシュ | プロンプトキャッシュ |
|---|---|---|
| 動作する層 | API/アプリ層 | LLM/推論エンジン内部 |
| LLMに届くか | 届かない | 届く |
| 判定基準 | 質問の意味の類似度 | プロンプトの固定部分の一致 |
| 削減対象 | LLM呼び出しそのもの | 入力トークンの解釈コスト |
| 出力の決定性 | 過去の回答をそのまま返す | 毎回新しく生成 |
| 実装場所 | 自社アプリに組み込む | プロバイダー側で対応(アプリ層はキャッシュを使うようにパラメータを指定) |
| 効きやすい条件 | 同じ意味の質問が繰り返されるケース | 長い固定の前置きが毎回送られるケース |
また、この2つは競合せず、組み合わせて使うこともできます。セマンティックキャッシュでヒットしなかった質問をLLMに投げ、その際にプロンプトキャッシュで入力処理を高速化するということも可能です。
※本稿執筆時点(2026年5月)の情報です。TTLの長さ、最低トークン数、対応モデル、課金方式などは各ベンダーで頻繁にアップデートされるため、実装時には必ず最新の公式ドキュメントを参照してください。
補足:「コンテキストキャッシュ」という用語について
ここで一点、用語の整理をしておきます。LLM関連の記事を読んでいると、コンテキストキャッシュ(ContextCaching)という言葉に出会うことがあります。「これはプロンプトキャッシュと違うものなのか?」という疑問を持たれた方もいるかもしれません。
結論から言えば、コンテキストキャッシュはプロンプトキャッシュと同じカテゴリの技術です。どちらもLLM内部で「同じ前置きの計算結果を使い回す」仕組みであり、働く層も効果も基本的には同じです。
ただし、ベンダーごとに名称や仕様が異なる点には注意が必要です。
- AnthropicClaude:名称は「PromptCaching」。自動で動作するモードとキャッシュの対象を明示的に指定するモードとがある。
- GoogleGemini:名称は「ContextCaching」。自動で動作するモードと、キャッシュの対象を明示的に指定するモードとがある。テキスト以外に動画・音声にも対応。
- OpenAIGPT:名称は「PromptCaching」。設定不要で自動的に機能する。
本稿ではこれらLLM内部のキャッシュ機構を総称して「プロンプトキャッシュ」と呼んでいます。
AIエージェント開発の実体験
ここからは、私たちが法人向けAIエージェント「BizAigent」の開発で実際に直面した問題を共有します。技術的な詳細は弊社エンジニアがZenn記事でも公開しています。
ほぼ自分しか使ってないのに利用料が高い
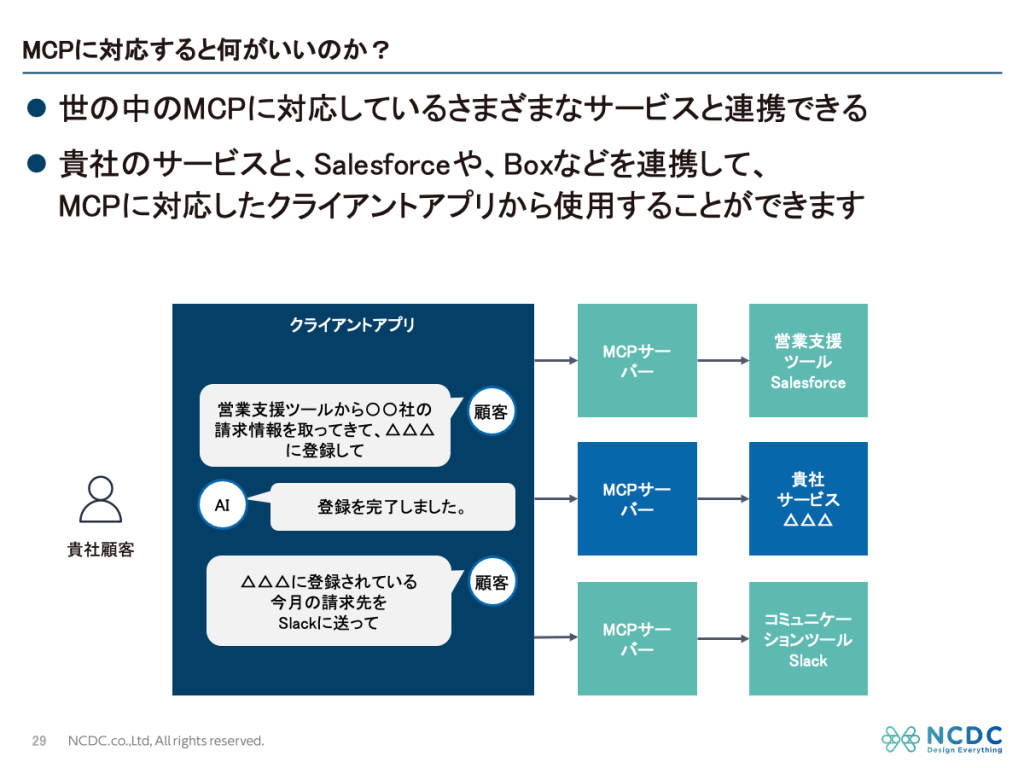
BizAigentは、Box、Slack、Gmailといった社内システムとMCPサーバー(AIモデルと外部データソースやツールを接続するためのサーバー)経由で連携し、業務タスクを自動実行する法人向けAIエージェントです。
開発中、社内検証で使っているだけなのに生成AI利用料が異常に高額になっていることに気付きました。ログを取って調べてみると、以下の事実が判明しました。
ユーザーが「こんにちは」と5文字打っただけのリクエストで、入力トークンが約21,786トークン消費されていたのです。
たった一言の挨拶で、大量のトークンが消費されている。これでは本番運用は到底成り立ちません。
原因はMCPツール定義の肥大化
調べてみると、原因はMCPサーバー連携で渡されるツール定義にありました。
MCPでは、AIエージェントが使えるツール(例:Boxのファイル検索、Slackのメッセージ送信など)を、毎回LLMに「使えるツール一覧」として伝える必要があります。1ツールあたりの定義は約1,000文字。BoxのMCPサーバーだけで10個以上のツールがあるため、それだけで1万文字超。複数のMCPサーバーを連携すると、10万文字を超えることもあります。
ユーザーが「こんにちは」と打っても、その裏では毎回数万文字のデータがLLMに送られ、その全文に対して課金されていたわけです。
プロンプトキャッシュ活用で97.5%の再利用に成功、コスト75〜80%削減
このコスト構造のままでは、本番運用に耐えられません。そこでAnthropicClaudeのプロンプトキャッシュを有効化しました。
MCPのツール定義はリクエストごとに変わらない完全に固定の前置きなので、プロンプトキャッシュとの相性は良く、結果は以下の通りでした。
- 入力トークン21,786のうち、21,097トークン(97.5%)の再利用に成功
- 金額ベースで75〜80%のコスト削減
- レイテンシも体感で大幅に改善
「ほぼ自分しか使ってないのに高い」状態から、本番展開に耐えるコスト効率まで一気に改善ができました。
この経験から得た教訓
AIエージェントを業務で本気で運用するなら、プロンプトキャッシュは必須です。特にMCPや複数のツール連携を使うエージェント型用途では、有効化するかしないかで、コストが大きく異なります。
ユースケース別:セマンティックキャッシュかプロンプトキャッシュか
生成AIの業務活用でよくあるユースケースについて、どちらのキャッシュがどう効くのかを整理します。
ケース1:社内ヘルプデスクのチャットボット
社内FAQ系のチャットボットでは、「経費精算の締切はいつですか」「経費精算の締切日は?」のように、同じ意味の質問が毎日繰り返し届きます。
- 効くキャッシュ:セマンティックキャッシュ
- 理由:よくある質問に一度回答すればキャッシュに乗り、以降はLLMを呼ばずに数十ミリ秒で返答できる
- 注意点:「私の有給日数は?」のように個人や時期に依存する質問まで意味類似度でマッチさせると、誤った回答を返してしまう。
ケース2:社内文書検索(RAG)
社内規定や技術文書など外部の文書データベースから関連情報を検索し、その文書をもとに回答の精度を高めるRAG構成。
- 効くキャッシュ:プロンプトキャッシュ
- 理由:RAGではシステムプロンプト・回答ルール・検索でヒットした文書本文など、毎回数千トークンに及ぶ大量の入力をLLMに渡すため。システムプロンプトや回答ルールは固定なのでキャッシュが有効
ケース3:AIエージェント(タスク自動化)
メール作成、データ集計、社内システムの操作などをLLMに任せるエージェント型の用途。前述のBizAigentはこのカテゴリです。
- 効くキャッシュ:プロンプトキャッシュ(特に有効)
- 理由:
- MCPやツール定義による巨大な前置きがある
- エージェントは1タスクで何度もLLMを呼ぶ(平均5〜20回)
- システムプロンプト・業務ルールが共通
ケース4:カスタマーサポートの一次対応
毎月の報告書を同じフォーマットで要約する、決まったテンプレートに沿って文章を整形する、定型文を英語に翻訳する、といった処理。
- 効くキャッシュ:プロンプトキャッシュ
- 理由:処理ルールやフォーマット指示などの「お決まりの前置き」が毎回同じで、変わるのは対象テキストだけという構造のため、キャッシュとの相性が良い
ケース5:要約・整形・翻訳などの定型処理
毎月の報告書を同じフォーマットで要約する、決まったテンプレートに沿って文章を整形する、定型文を英語に翻訳する、といった処理。
- 効くキャッシュ:プロンプトキャッシュ
- 理由:処理ルールやフォーマット指示などの「お決まりの前置き」が毎回同じで、変わるのは対象テキストだけという構造のため、キャッシュとの相性が良い
キャッシュ導入で陥りがちな落とし穴
キャッシュ導入時に起こりがちな代表的な落とし穴には次のようなものがあります。
プロンプトキャッシュの落とし穴
プロンプト順序を意識せず、プロンプトキャッシュが効いていない
プロンプトキャッシュは「前方に固定の内容、末尾にユーザーごとに変わる内容」を配置するのが基本です。可変要素を先頭に置いてしまうと、有効化したつもりでも全くヒットしないことがあります。
※ベンダー、キャッシュ方式によって異なります
ベンダーごとのキャッシュ仕様の違いを把握していない
プロンプトキャッシュは、AnthropicClaude、GoogleGemini、OpenAIなど、ベンダーごとに名称・最低トークン数・TTL・課金方式・キャッシュの一致判定方法が異なります。
また、同じベンダーでもキャッシュの指定方法(明示的か暗黙的かなど)が異なったりします。
仕様を理解せずに使うと、想定したヒット率が得られないことがあります。
実装時には必ず最新の公式ドキュメントを確認することが重要です。
セマンティックキャッシュの落とし穴
類似度閾値の設定が不適切
閾値が緩すぎると誤った回答につながり、厳しすぎるとキャッシュがほとんど機能しなくなります。業務の内容に応じた調整と回答精度の継続的な評価が必要です。
キャッシュの更新・削除タイミングが定められていない
社内規定の改定や料金表の更新があった際に、古いキャッシュをそのまま残してしまうと、AIが古い情報をもとに回答し続けてしまいます。古いキャッシュを見直すタイミングを設定することで、誤答を防ぐ必要があります。
権限スコープを越えてキャッシュが共有されてしまう
セマンティックキャッシュは、過去の回答を別の質問にも使い回す仕組みです。
問題なのは、回答を生成した時のユーザーと、キャッシュから回答を受け取るユーザーで、本来アクセスできる情報の範囲が違う場合です。例えば管理職向けに生成された売上情報が、一般社員にも返されてしまうといった事故が起こり得ます。
キャッシュの対象は、「誰が見ても問題のない汎用的な情報」に限定することが基本です。
- キャッシュしてよいもの:FAQ回答、業務手順、一般的な説明文、定型テンプレートなど
- キャッシュしてはいけないもの:特定の個人に関する情報、社外秘の数値・契約内容、人事・給与情報など
「最新の回答が出ない」ユーザー体験を放置する
セマンティックキャッシュを導入すると、「AIに聞いたのに古い情報が返ってきた」というユーザーの戸惑いが生じることがあります。
「回答の末尾にキャッシュ日時(最終更新日)を表示する」「ユーザーがキャッシュを無効化して再質問できる導線を用意する」などの対処法を用意することで、ユーザー体験が損なわれないよう工夫することが必要です。
キャッシュ以外の生成AIコスト最適化の方法
キャッシュは強力なコスト削減手段ですが、それだけですべてが解決するわけではありません。以下のチェックリストも合わせて確認することで、より総合的なコスト最適化が実現できます。
モデル選定:高性能モデルは必要な場面だけ
生成AIには、高性能・高コストなモデルから、軽量・低コストなモデルまで複数の選択肢があります。すべての処理に最高性能のモデルを使う必要はありません。
複雑な分析や高度な文章生成には高性能モデル、単純な要約や定型文の生成には軽量モデル、という使い分けだけで、コストを大幅に抑えられることがあります。
プロンプトを短くする:不要な前置き・重複の削減
プロンプトが長ければ長いほど、消費するトークンが増えます。丁寧に書こうとするあまり、同じ内容を繰り返したり、不要な前置きを加えたりしているケースは少なくありません。
要点を絞って簡潔に指示するほうが、コストを抑えながら精度の高い回答を得やすくなります。プロンプトの見直しは、すぐに取り組めるコスト削減策のひとつです。
ただし、プロンプトキャッシュを使う場合は注意が必要です。先述のように、単にプロンプトを短くするのではなく、「固定部分は長く保つ」ほうが、キャッシュヒット率の観点では有利になることがあります。
まとめ:2つのキャッシュを使い分ける
セマンティックキャッシュとプロンプトキャッシュは、似た名前ながら働く層が違うため、効果も使いどころも別物です。
- セマンティックキャッシュ=アプリ層で「LLMを呼び出すかどうか」を判断する仕組み
- プロンプトキャッシュ=LLM内部で「計算を使い回す」仕組み
業務における生成AIの運用フェーズでは、この2つのどちらを、どこに、どう組み合わせるかが、コストとレスポンス速度を左右します。
BizAigentの開発を通じて実感したのは、「動くものを作る」と「コストとレスポンスに耐えられるものを作る」の間には大きなギャップがあるということです。そしてそのギャップを埋める打ち手のひとつが、本稿で紹介したキャッシュ戦略です。
「動かしてみたが、コストが想定より高い」「レスポンスが遅くてユーザーから不満が出ている」といった場合、キャッシュの設計を見直すことで改善できる余地があるかもしれません。
業務用AIエージェント開発・コスト最適化はNCDCにご相談ください
NCDCでは、法人向けAIエージェント「BizAigent」の開発・提供で得た知見をベースに、業務向けAIアプリケーション・チャットボット等の開発を支援しています。
技術的な実装だけでなく、業務フローの整理や運用体制の設計まで含めて考えることが、コスト最適化を成功させるうえで欠かせません。
- 既存のAIアプリのコスト・レスポンスを改善したい
- 業務にAIエージェントを導入したいが、本番運用に耐える設計にしたい
- MCPやRAGを使ったAI連携を検討しているが、コスト構造が読めない
- 社内の問い合わせ対応・文書検索・務自動化をAIで実現したい
- 「まず何から始めればいいかを整理したい」ので相談がしたい
このようなお悩みがあれば、ぜひお気軽にお問い合わせください。現状のアーキテクチャ診断から、キャッシュ戦略を含めた最適化設計、本番運用まで、貴社の状況に応じて伴走支援いたします。


-300x204.jpg)