目次
2025年5月22日にオンラインセミナー『AWS活用による現場データの収集・活用自動化のポイント』を開催いたしました。
この記事では当日用いた資料を公開し、そのポイントを解説しています。
1. 現場データ活用の現状と課題
近年、現場データの活用が急速に進んでいます。特にPOSやEコマースによる販売記録、そして M2Mデータを含む自動取得データの活用が大きく進展していることが、2020年の総務省のデータからも伺えます。このような状況は、各企業におけるIoTの導入加速によってもたらされています。

現場で自動取得されたデータは、経営企画、組織改革、製品・サービスの企画開発、マーケティングといった多岐にわたる領域で活用されています。
先の情報源は2020年のものですが、センサーデバイスの低価格化や通信技術の発展によりIoT導入は近年も加速し続けており、多くの企業がIoTによる自動取得データの活用に取り組んでいると推測されます。
しかし、現場データの活用が進む一方で、データ活用までの各段階や活用時における課題も見えてきています。特に、熟練者の知見に依存する複雑な判断業務や、構築後の AI モデルの安定運用といった領域は、従来のシステムや手動管理では限界があります。 そこで、クラウドが提供する AI/機械学習(ML)技術と、それらを業務に組み込む自動化の仕組みが、解決の鍵となります。
よくある課題と解決策の例を以下に示します。
- 課題:熟練者の知見に依存した判断業務の属人化
- 解決策の例:熟練者による判断基準をダッシュボードなどで可視化し、誰もが見える仕組みを構築します。また、熟練者の経験や判断プロセスを機械学習で学習させ、AIモデルを構築して判断を補助します。
- 課題:分析モデルの構築・運用の属人化と継続活用の困難さ
- 解決策の例:モデルの構築から運用までを自動化し、再現性と継続性を担保するMLOpsの仕組みを導入します。
このように、効率的なデータ活用を実現するためには、クラウドやAIによる自動化技術が大きな助けとなります。
2. 自動化における2つのポイント
「AIを使って仕組みを便利にしたい」という思いを持っている一方で、その実現方法に悩む方は少なくありません。
複雑なデータ処理やAIモデルの運用、そして将来的なスケールを必要とする自動化の仕組みを構築するには、スケーラビリティ、柔軟性、そしてAI/MLサービスを統合的に提供するクラウド基盤が不可欠です。
AWSは、まさにその要求に応える豊富なサービス群と実績を持つプラットフォームであり、課題の解決へ向けたさまざまな自動化の仕組みを構築することが可能です。
この自動化を成功させるためには、単なる技術の話に留まらず「何を自動化するか」と「どのように業務に組み込むか」という2つの視点が大切です。
1. 何を自動化するか
IoTセンサーや設備からのデータ取得を自動化することで、現場データを正確かつタイムリーに収集・把握できるようになります。
AIモデルの活用と運用を自動化することで、分析業務の属人化を防ぎ、新しいデータに基づいて継続的に改善できる仕組みを構築できます。
2. どのように業務へ組み込むか
分析・AI活用の業務組み込みとして、ダッシュボードやBIツールなどで情報を可視化し、現場で日常的に使える形にすることで実現できます。
AIの推論結果に基づいて、通知やアラートなどで利用者に気づきを与える仕組みも構築可能です。分析に基づいた判断や作業を自動で実行できるプロセスを構築することも可能です。
3. データ活用ステップと課題解決アプローチ
データ活用には、収集・蓄積、準備・加工、分析、そして活用といったステップが存在します。そして、各ステップには躓きやすい課題や、実際にその取り組みをはじめた後で直面する運用の壁が存在します。
下図は、各ステップの「よくある課題」をまとめたものです。

この下の図では、各ステップの「よくある課題」に対して、現場での改善や仕組み化を実現するための解決アプローチを整理しました。
それぞれのアプローチに対して、「どの仕組みを自動化するか」そして「どのように業務を組み込むか」という観点から、自動化の目的と期待される効果を明確にしていきます。

自動化を考える際のポイント
ここまで、課題から解決アプローチと自動化の目的・効果を考えてきました。改めて自動化を考える際のポイントについて整理します。
- 自動化の目的を明確にする:自動化によってどのような効果を得たいかを明確にすることが重要です。自動化はあくまで手段であり、目的と混同しないよう注意が必要です。
- 自動化によって得られる効果を意識する:効果の種類を明確にすることで、自動化の目的や優先度を判断しやすくなります。また、本格導入前のPoC(概念実証)における評価測定の指標ともなります。
効果は定量的な効果と定性的な効果の2つに分けられます。
定量的な効果とは数値で測定できるもので、投資対効果を示しやすく導入判断をしやすい特徴があります。 例えば、作業時間の一日〇時間削減、年間〇万円のコスト削減などが挙げられます。
定性的な効果とは数値で測りづらいものですが、品質や働きやすさ、ビジネス全体の改善につながる特徴があります。 例えば、業務が簡単になった、部門間で共通認識ができるようになったなどが挙げられます。
原則として定量的に測定できるものを効果の指標に含めます。一方で、定性的な効果も大切であると考える場合は、アンケートなどで可視化し、定量的に把握できるようにする工夫が必要です。
さらに、得られる効果がビジネス的にどう寄与するのかも意識してみることが重要です。 例えば、分析結果をダッシュボードで可視化した効果について考えてみます。
まず、利用者が状況を直感的に把握できることで、意思決定の迅速化や業務の納得感の向上といった定性的な効果が生まれるでしょう。
次に、ダッシュボード活用を定着させることで、異常検知の早期化や対応時間の短縮など、数値で測れる定量的な効果も考えられます。
分析結果のダッシュボード可視化は、技術的な話というよりも業務的な工夫、つまり「どう業務に生かすか」という2つ目のポイントに当たります。一見すると定性的な効果が強く見えますが、このように深掘りしていくと定量的な効果も考えられるため、効果について考える際にはじっくり検討してみることをお勧めします。
4. AWSサービスによるデータ活用基盤の実現
データ活用に必要な仕組み
データ活用までのステップを実現するには、各工程を支える基盤となる仕組みを整える必要があります。特にデータを蓄積して整え、分析・活用へとつなぐためには、データレイクやデータウェアハウスといった構成要素が重要な役割を担います。

まずは収集したデータをデータレイクに保管します。次に、データレイクからデータを取り出し、構造化してデータウェアハウスやデータマートに格納します。構造化されたデータを分析・可視化し、それを業務活用につなげる仕組みを構築します。
データが蓄積場所に保管されるまでの間や、分析・活用に至るまでの過程においては、必要に応じてデータ加工などの処理を組み込むことが可能です。

また、データウェアハウスを経由せず、直接分析するケースがあります。
- リアルタイム性が求められるケース
- 機械学習モデルの構築・トレーニングに活用するケース
- 事前に定義された集計では対応できないケース
新たな視点で分析をおこないたい、複数のデータを横断的に分析したいケースなどでは、データレイクに貯めたデータを直接活用する構成がよく取られます。
上記はあくまで例ですので、データの形式や分析目的に応じて最適な構成を選ぶことが重要です。
データ活用をAWSで実現
AWSは豊富なサービスを提供しており、データ活用における一連の流れをカバーすることが可能です。目的に応じてサービスを組み合わせることで、PoCなどのスモールスタートから本格運用まで対応可能な基盤を構築できます。

データ活用を実現するプロセスを「データ収集」「データ蓄積」「データ分析」「データ活用」という4つのステップに分けて考えたいと思います。ここでは、それぞれのステップの役割について解説します。
データ収集
まずはデータ活用の元となるものを収集します。
エッジデバイス(センサーやカメラなど)や、社内外の既存システムから得られるものなど、あらゆるデータが対象となります。
データ収集の方法は多様です。エッジデバイスからの収集では、デバイス側とクラウド側のサービスがセットで提供されていることが一般的です。また、外部アプリケーションからクラウドへデータを集約するために、クラウド側にAPIなどの「受け口」を用意するアプローチも広く採用されています。
データ転送や取り込みのための専用サービスも豊富に用意されています。これにより、収集対象のデータ形式(ファイル、ストリーミング、データベースなど)や、データが存在する環境(オンプレミス、他社クラウドなど)に柔軟に対応し、環境に合わせた最適な収集手段を選択することが可能です。
データ蓄積
収集したデータは、後続の処理で利用しやすいように一箇所に集約・蓄積します。
収集されたデータの多くは、まず Amazon S3 のようなオブジェクトストレージに集約されます。 S3は、あらゆる形式のデータをそのままの形式で大規模に保存できる「データレイク」の代表的なサービスです。
ただし、データの特性や目的に応じて最適な蓄積場所を選択することも重要です。例えば、時系列データやストリーミングデータに特化した専用のデータベースも存在します。
分析用途に最適化された「データウェアハウス(DWH)」としては、Amazon Redshift が広く利用されています。S3 に蓄積した生データを加工・整形し、分析基盤である Redshift に取り込む構成は、データ分析の一般的なパターンの一つです。このほか、リレーショナルデータベースを介して、直接業務アプリケーションにデータを組み込み活用する構成も考えられます。
データ分析
蓄積したデータを分析し、ビジネス上の洞察を得るステップです。
データの可視化(BIツールによるダッシュボード作成)から、AIモデルの構築(予測・異常検知のための機械学習)、アドホックな集計・分析まで、目的に応じて多様なツールやサービスを使い分けます。扱うデータの規模、求められるリアルタイム性、分析手法の複雑さなど、要件に応じて最適なサービスを選択することが求められます。
データ活用
分析によって得られた知見を、具体的なビジネスアクションに結びつけ業務を「自動化」する、データ活用の最終ステップです。
専用のサービスを活用することで、分析結果に基づいた業務プロセスの自動化、関係者へのアラート通知、あるいは既存の業務アプリケーションへの分析結果の組み込み(レコメンド機能の実装など)を実現します。このステップにより、データが「分析して終わり」ではなく、具体的な業務改善や新たな価値創出に繋がり、データ活用のサイクルが完結します。
データ活用基盤構築の4つのポイント
- 元データを保持すること
将来の分析ニーズや再利用に備え、元データを保持しておくことが重要です。柔軟な分析や再検証を可能にするために、S3のようなデータレイクへの保持が適切です。
- データ形式や目的に応じて柔軟に構成を選ぶこと
ストリーミングデータ、バッチ処理、構造化データ、非構造化データなど、用途ごとに最適な処理・分析方法が異なります。データレイクから直接分析するケースや、データウェアハウスに整理して使うケースなど、状況に応じて構成を選ぶことが大切です。
- スケーラビリティを考慮すること
データは継続的に蓄積されるため、最初から増える前提で設計することが重要です。S3や Redshiftなど、スケール可能なサービスを使うことで、無理のない運用が可能となります。
- マネージドサービスを活用し、変化に対応すること
ビジネスニーズや分析対象は変化するため、構築後も変化に追随できる再構築性を持つことが大切です。AWSではマネージドサービスが用意されており、これらを活用することでインフラ管理の負担を減らし、本質的な業務に集中することが可能です。
このように、AWS ではこれらのポイントを踏まえて目的に応じてサービスを組み合わせ、柔軟に使い分けることが重要です。
また、一度構築して終わりではなく、ビジネスの変化や技術の進歩に合わせて構成を少しずつ見直すことも必要になります。この「継続的な改善」の視点こそが、自動化された仕組みを長期的に安定して活用するために不可欠な要素です。
5. 自動化の具体的なユースケース事例
AWSを活用した自動化のユースケースを3つ紹介します。
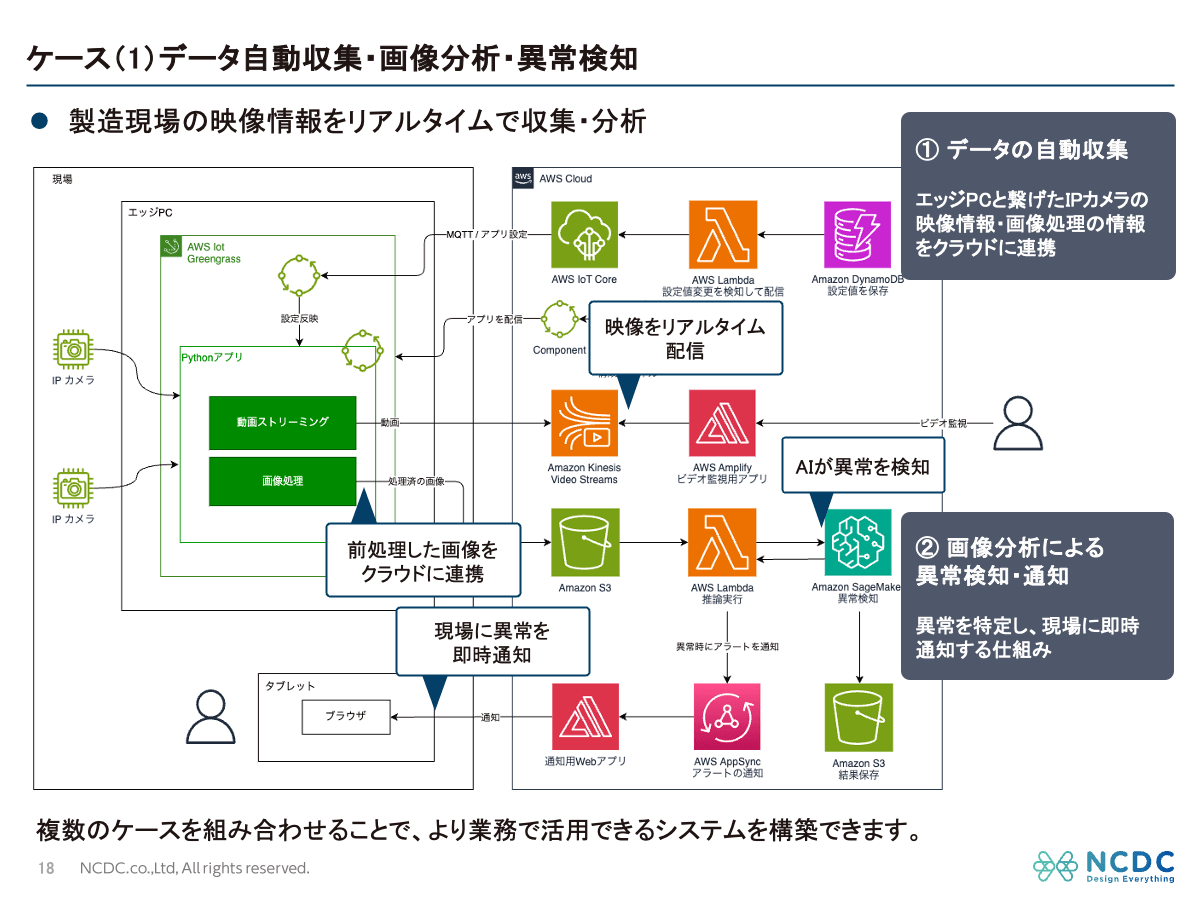
データ自動収集・画像分析・異常検知

IPカメラの映像を Amazon Kinesis Video Streams で受信し、AI が画像をリアルタイムで分析します。異常を検知した場合、現場へ即座にアラートを自動通知する仕組みです。人間の目視を超える速度と精度で、迅速な対応と品質管理の向上を可能にします。このように複数のケースを組み合わせることで、より業務で活用できるシステムを構築することが可能です。
データの可視化・モデルを活用した予測

複数のシステムからデータを自動集約し、S3 に統合します。この統合データで予測モデルを構築し、計画立案などの予測処理を自動で実行します。推論結果を業務アプリケーションに直接反映・可視化することで、迅速かつデータに基づく意思決定プロセスを自動で支援する仕組みです。
モデル学習・更新の自動実行

データの前処理からモデル学習、デプロイ、推論処理といった AI モデルのライフサイクル全体を ML パイプラインとして構築し、定期実行・自動運用を実現します。これにより、モデルの性能を常に最新の状態に保ち、AI 活用を持続的かつ安定的に実現し、運用の属人化を解消します。これらをMLパイプラインとして定期実行する仕組みを構築します。モデルの更新・運用を自動化することで、属人化の解消と管理工数の削減を可能にした例となります。MLOpsの詳細については、弊社のコラムもご参照ください。
6. まとめ
本記事では、現場データ活用における具体的な課題と、AWS のサービスを活用した AI 自動化の仕組みをご紹介しました。
自動化を推進し、その効果を最大限に引き出すために、以下の重要なポイントを意識しましょう。
- 自動化の目的を明確にする
ビジネスへの貢献(定量効果)と業務の質的改善(定性効果)のどちらに寄与するかを事前に定義し、目的を明確にする。 - データ活用基盤を適切に構築する
S3へのローデータ保持を基本とし、データの変化や量に耐えうるスケーラビリティと、柔軟な運用を可能にするマネージドサービスの活用を考慮して設計する。
これらのポイントを踏まえ、まずはリスクを抑えた形で、具体的なアクションに取り組んでみましょう。自動化実現に向けた第一歩として、以下の行動にぜひ取り組んでみてください。
- 現場に存在する課題を一つ明確にし、小さな範囲で PoC(概念実証)のアイデアを立ててみる。
- AWS の無料利用枠を活用し、簡単なデータ収集や可視化といったスモールステップを実践し、自動化の実現可能性を探る。
自動化は、自社の課題解決と新たな価値創造のための強力なツールです。ぜひ次のステップにお役立てください。本日ご紹介したユースケースも参考になれば幸いです。
AWSを活用した「現場データの自動化」のご相談はNCDCへ
NCDCでは、AWSの機能を活用して、「現場データの自動収集」から「AIによる分析・業務への活用」までをトータルでサポートします。 難しい技術の選定や仕組みづくりについても、お客様の課題に合わせてご支援します。「手作業の集計業務を自動化したい」「AWSを使って、まずは小さくデータ活用を始めてみたい」という方は、ぜひお気軽にご相談ください。