目次
2025年3月28日にオンラインセミナー『AI×データ活用実践ノウハウ。埋もれたデータを“使える資産”に変えるには?』を開催いたしました。 この記事では当日用いた資料を公開し、そのポイントを解説しています。
はじめに
経済産業省がDXを「企業がビジネス環境の激しい変化に対応し、データとデジタル技術を活用して、顧客や社会のニーズを基に、製品やサービス、ビジネスモデルを変革するとともに、業務そのものや、組織、プロセス、企業文化・風土を変革し、競争上の優位性を確立すること」※1と定義しているように、データの活用はDXの核を成す要素だと言えます。
※1 経済産業省 デジタルガバナンス・コード 実践の手引2.0より
しかし現状は、多くの企業において、必ずしもデータ活用が順調に進んでいるとは言えません。
そこで、本記事では「データはあるけれど活用できない」「活用方法がわからない」という課題を抱えている方向けに、「AI×データ活用」実践ノウハウを解説していきます。
AI活用における現状と課題
上司や経営層から「データも溜まっているし、AIを活用して何か取り組んでみてはどうか」と求められ、どうすればいいのかと戸惑った経験をお持ちの方も多いのではないでしょうか。AIを活用するために何をすればいいのか? 本当に持っているデータが活かせるのか? とった疑問は、整理すると大きく4つの視点に分けて考えられます。
- 何をすればいいの?: ①テーマを設定する
- AIってそんな簡単に使えるの?: ②AI活用環境を準備する
- 確かにデータは溜まっているけれど、使えるの?: ③使えるデータを準備する
- 何かできたらみんな使ってくれるの?: ④AIの推論根拠を可視化する
これらの4つの視点について、順にご説明していきます。
AI×データ活用①テーマを設定する
分析テーマの設定
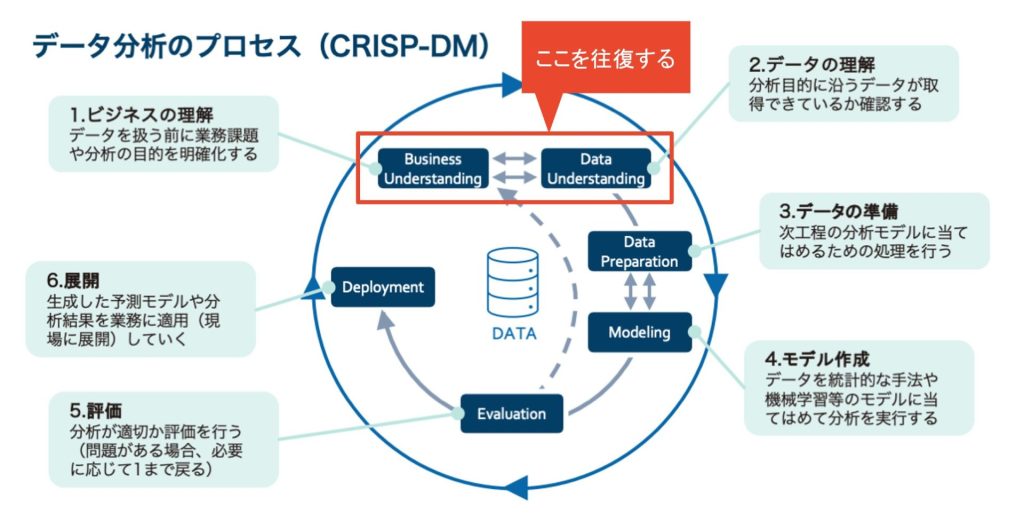
上図は CRISP-DM(Cross Industry Standard Process for Data Mining) と呼ばれるもので、業種・業界に関わらず、データ分析を行う際に採用すべき標準的なプロセス体系を示しています。
プロセスは「ビジネス理解」から始まり、「展開」で一旦完結しますが、ウォーターフォール型のように明確な始まりと終わりがあるわけではありません。 プロセス間を何度も往復しながら精度を高めていく のが特徴です。
最初のステップである「ビジネス理解」では、業務課題の明確化が重要です。ただし、実際には「定義した課題を解決するためのデータが存在しない」というケースも多く見られます。そのため、「ビジネス理解」と「データ理解」を行き来しながら、 課題とデータをすり合わせていくこと が効果的です。図の双方向矢印が示すように、ビジネス視点とデータ視点の両面からテーマを設定することが、分析成功の鍵となります。
分析テーマ設定のヒント
日々の業務で感じる「課題」や「もっとこうしたい」という思いを、手元のデータで解決できるかどうかを検討することが、テーマ設定の出発点です。
重要なのは、「やりたいことがデータで実現できるか」と「データから何ができるか」という 双方向の視点 を持つことです。
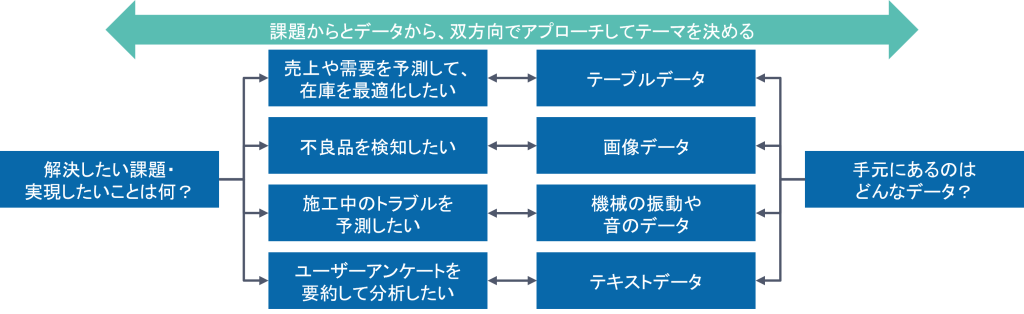
例えば「売上や需要を予測して在庫を最適化したい」としても、受発注データや在庫データがなければ分析は始まりません。
一方で、既に受発注や在庫のデータが整っている場合は、「このデータを活用して需要予測ができるのでは」とデータ起点でテーマを見出すこともできます。例えば不良品検知も同様で、「製造工程で製品の画像をたくさん撮っているけれど、これって何か使えないかな?不良品の検知ができるのではないか?」といった発想で、データ分析を前に進めることも可能です。
こうした考え方を踏まえた分析テーマ設定の具体例を3つご紹介します。
分析テーマ設定の例
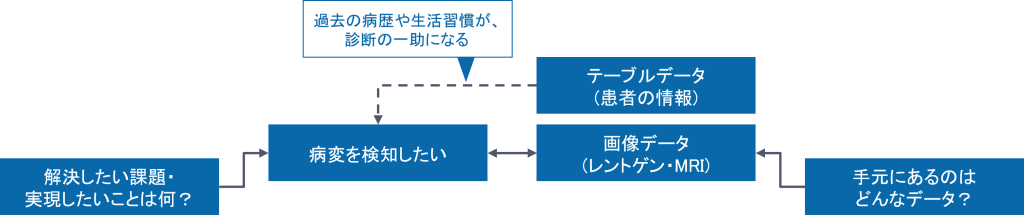
1. 病院における画像診断
- 課題・やりたいこと
- 経験の浅い医師が病変を見逃し、重大な誤診につながることを避けたい
- 診断にかかる時間を短縮し、患者への診断結果通知を速やかに行いたい
- ベテラン医師の知見を、 効率よく次世代に伝承していきたい
- データ
- レントゲンやMRI等、 診断するための画像は大量に蓄積されている
- カルテの情報も電子化されつつある
- テーマ
- 画像を用いて「病変がどのように画像に現れるか」をAIに学習させ、診断に活用する
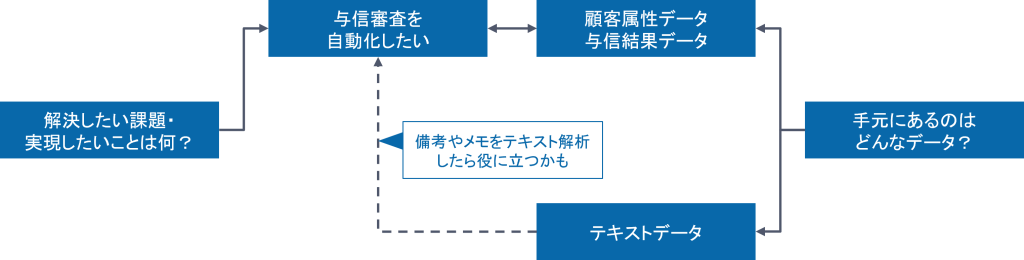
2. 金融機関における与信審査
- 課題・やりたいこと
- 与信の審査には時間がかかり、融資業務のボトルネックになっている
- 審査にかかる時間を短縮し、行える融資は速やかに行いたい
- リスクを見逃さず、審査ミスによる融資の焦げつきを減らしたい
- データ
- これまでの審査データは大量に保存されている
- どんな属性の人がいくらの融資を申請し、承認したか・しなかったか
- テーマ
- 顧客の属性情報と審査承認の有無をAIに学習させ、与信審査を自動化する
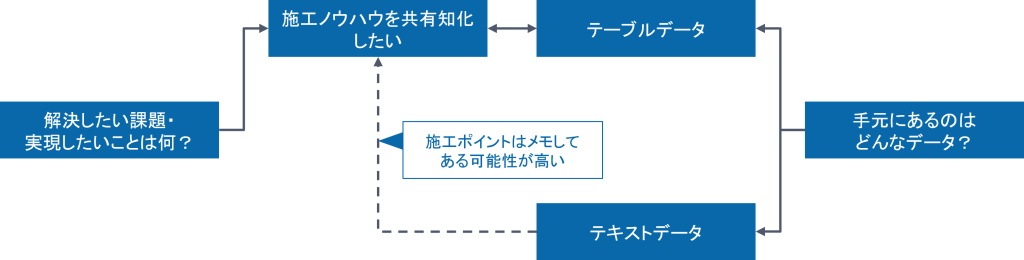
3. 建設業における施工管理
- 課題・やりたいこと
- 現場や担当者によって、工事の品質に差がある
- 工事品質を向上させるノウハウを次世代に伝えていきたいが、ノウハウが属人化している
- データ
- これまで自社で担当してきた工事の結果を記録したデータはある
- 敷地面積・建物の階数・工期等の定量的なデータだけでなく、備考欄に書かれた注意事項のようなテキストデータも存在する
- テーマ
- 施工品質と合わせて工事の属性(地点・工法・その他諸条件)をAIに学習させ、属人的なノウハウの抽出を試みる
AI×データ活用②AI活用環境を準備する
AI活用環境の整備は難しくない
生成AIに限らず、AIに関連する製品やサービスは非常に多岐にわたります。しかし、業務の中でAIを適用するとなると、市販の製品を導入するだけでは実現できないものも出てきます。業務特有のデータ加工や、モデルに対する業務特有の解釈が必要になる場合があるからです。とはいえ、自社でAI活用環境を整えることは決して難しくありません。
AWS、Google Cloud、Microsoft Azureといった主要クラウドでは、SageMaker、AutoML、Azure Machine Learningといった機械学習サービスが用意されており、簡単に試すことができます。
また、これらのサービスはモデリングや分析に留まらず、モデルの開発から運用までの一連のプロセスを効率化し、継続的に最適化するためMLOps(エムエルオプス)にも対応可能です。
MLOpsについては下記記事も併せてご覧ください
なぜMLOpsが必要なのか?基礎から自動化の具体例までわかりやすく解説
もしクラウド環境がない場合でも、Anaconda(アナコンダ) や KNIME(ナイム)といったツール・ソフトウェアがお勧めです。
今回取り上げたクラウドサービスや、Anaconda、KNIMEといったツールは、いずれも多様なアルゴリズムを扱えるようになっており、ニーズに合わせてモデリング方法も色々と選択できるようになっています。
ノーコードで始めるデータ分析 ― KNIMEの活用
特におすすめなのが、無料で使えるデータ分析ツール KNIME(ナイム) です。
KNIMEは、プログラムを組まずにGUIでフローを組むことで、データの可視化、特徴量作成、データ加工、そしてAIによるモデリングなどができます。
ExcelやCSVデータを読み込んで分析でき、スタンドアロンのPCでも動作します。日本語対応は限定的ですが、「AI活用をまず試してみたい」という段階には最適なツールです。
アルゴリズム選択に役立つチートシートとは
AIを活用する際、「どのアルゴリズムを使えばよいのか」と迷う方も多いでしょう。その際に役に立つのが、 アルゴリズム選択チートシート です。
今回は2種類のチートシートを代表的な例としてご紹介します。
scikit-learnアルゴリズムチートシート
 https://scikit-learn.org/stable/_downloads/b82bf6cd7438a351f19fac60fbc0d927/ml_map.svg
https://scikit-learn.org/stable/_downloads/b82bf6cd7438a351f19fac60fbc0d927/ml_map.svg
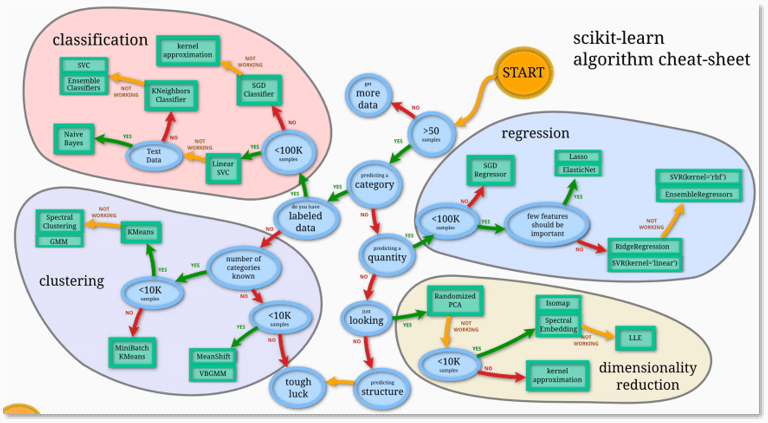
機械学習ライブラリscikit-learnのチートシートでは、 データ量や目的(分類・回帰など)に応じて適切なアルゴリズムを選べます 。
上図のとおり「START」から見ていくと、まず「データ数は50を超えていますか?」と問われます。50を超えていない場合は「もっとデータを集めなさい(More Data)」と示され、50を超えていれば「次へ進み、何を予測しますか?」と問われます。
次に、カテゴリー(例えば、イエスかノーか、不良品か正常品かといった分類)を予測するのか(分類問題)、あるいは株価や売上高のような数字をそのまま予測するのか(回帰問題)、といった選択肢があり、それぞれに進むべきアルゴリズムが緑の四角で示されています。
カテゴリーを分類する問題であれば、「教師データを持っていますか?」と問いかけ、持っていれば、データ数に応じて適切なアルゴリズム(例:10万サンプル未満ならLinearSVC、それ以上ならSGDClassifierなど)を提示してくれます。それでもうまくいかない場合は、別のアルゴリズムを試すよう促します。
このように、自分の手元にあるデータからたどっていくことで、何を使えばいいのかが分かりやすくなっているのがチートシートです。
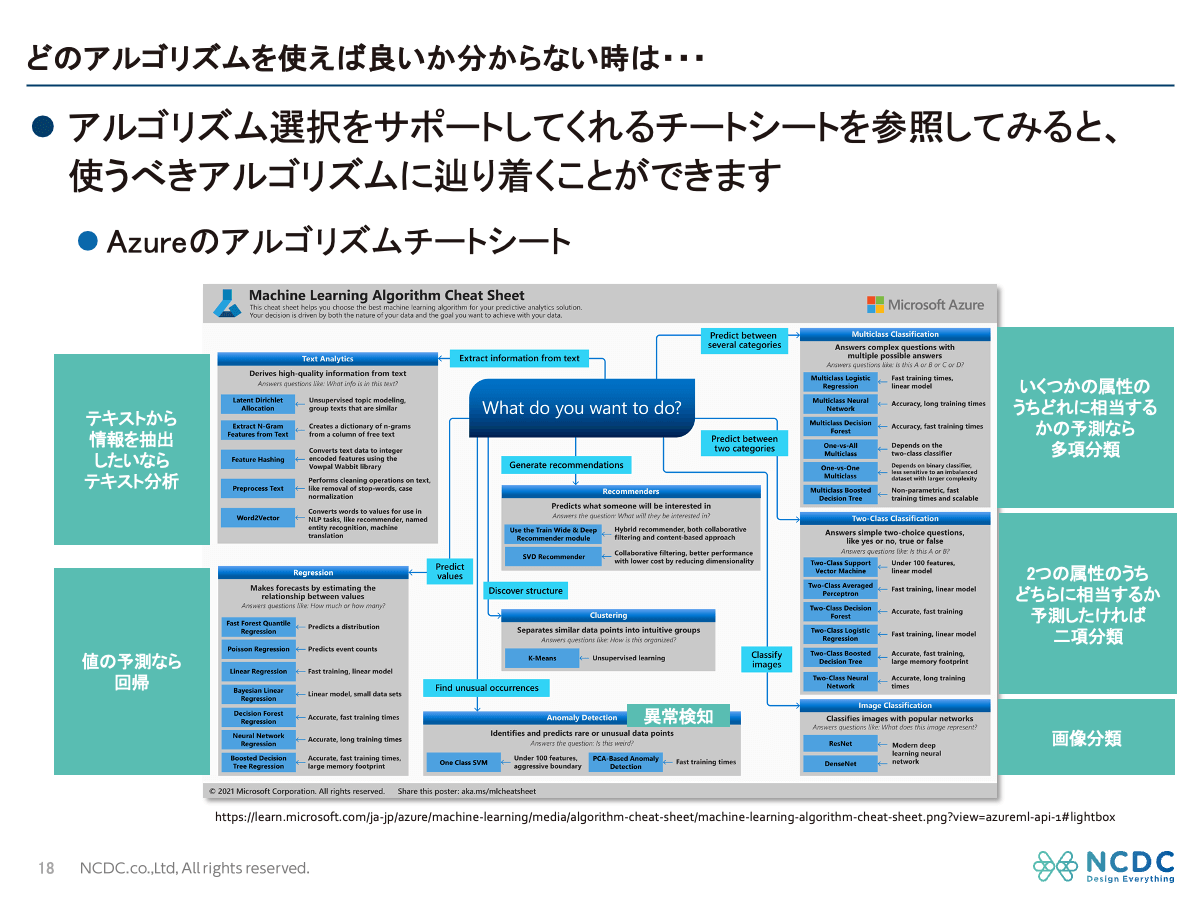
Microsoft Azure Machine Learning アルゴリズムチートシート
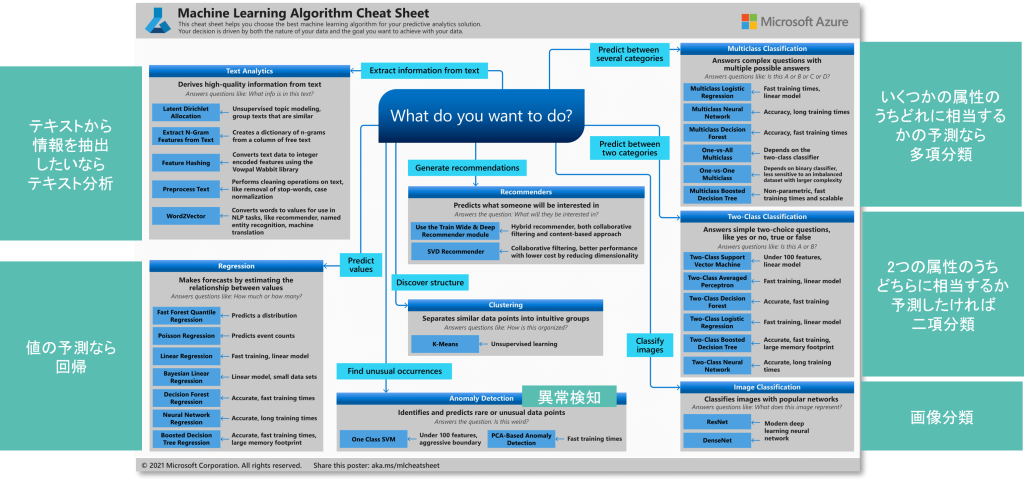
また、Microsoft Azure Machine Learningのチートシートでは、 「何をしたいか(分類・回帰・テキスト分析など)」から最適な手法を導く ことができます。
こちらは少し細かくなっていますが、上図の中央にある「何をしたいですか?(What do you want to do?)」という問いから始まります。
水色の四角で「こういうことをしたい場合は」という説明があり、例えば「テキストから何かしら情報を抽出したいならテキスト分析をしてください」「値の予測をしたいなら回帰分析をしてください」といった指示があります。
さらに、「いくつかの属性のうち、どれに予測するか」であれば「多項分類」、「二つの属性のうちどちらかに相当するか」であれば「二項分類」を選択します。画像分類についても「Classify Images」と示されています。
この中でもさらに細かく「こういうのを重視したければこれがいいでしょう」と書かれており、例えば「Multi-class Neural Network」は正確だが学習に時間がかかるといった説明があり、長い時間をかけても正確性が求められる分析をしたい場合に適していると示唆してくれます。
こうしたチートシートを活用すれば、専門知識がなくても自社の課題に合ったアルゴリズムを見つけやすくなります。
AI×データ活用③使えるデータを準備する
データの準備
テーマ設定とAIを使う環境が整ったら、次に確認すべきは「手元のデータがAIで活用できる状態かどうか」です。多くの場合、システムに蓄積されたデータはそのままでは使えず、加工が必要です。実際、データ分析工程の多くを占めるのがこの準備・加工作業であり、大きな工数がかかります。作業内容は、人間が見やすい形に整える データクレンジング と、機械が扱いやすい形に変換する 特徴量生成 に分けられます。これらを適切に行うことで、AIが有効に学習できる環境が整います。
データクレンジングと特徴量生成
- 欠損の除去・補完:手入力漏れやセンサーデータ欠損はAIが苦手とするため、0や平均値・中央値で補ったり、該当レコードを除去したりするなどの処理が必要です。
- 外れ値の除去:極端に外れた値を除去していくのが外れ値の除去です。例えば、気象データで最高気温が50℃というデータがあった場合、日本では記録されたことのない値なので、通常は誤りとして除外します。しかし、統計的には一見外れ値に見えるデータが、業務の文脈では外れ値ではないことも少なからずあります。そのため、慎重な判断を下していくことが求められます。
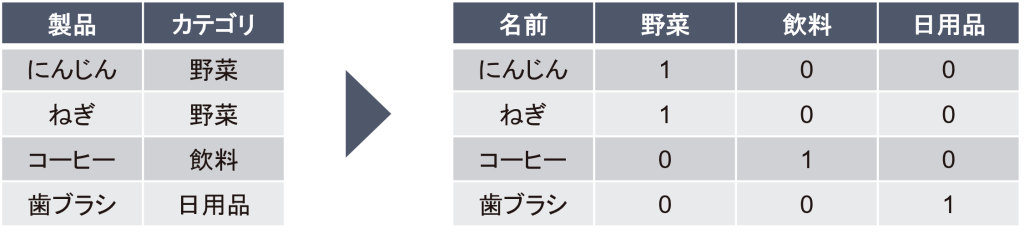
- カテゴリ型変数のダミー化:「にんじんは野菜カテゴリ、ねぎも野菜カテゴリ、コーヒーは飲料カテゴリ、歯ブラシは日用品カテゴリ」といったように分類されているものを、そのカテゴリの列を追加してフラグを立てていく作業をダミー化またはダミー変数化と呼びます。
これらの処理は手作業では膨大ですが、簡単なコードやGUIによる処理フローの作成(先ほどご紹介したKNIMEのようなツール)で実装することも可能です。
AI×データ活用④AIの推論根拠を可視化する
推論根拠の明確化
データが整い、AIが推論できるようになっても、実務で使われるとは限りません。ここで重要なのが 推論根拠の可視化 です。
推論の理由がわからないAIは信頼されず、業務に定着しないのです。ここからは、AIを「説明できるもの」にするための手法を解説します。
推論根拠が見えないことのリスク
AIアルゴリズム基本的にブラックボックスで、推論根拠が分かりません。AIの推論根拠が見えないと、重大な事案が発生する可能性もあります。
医療と金融の事例を挙げて説明します。
医療分野の事例
例えば、「これは癌です」とAIが出してきたものの、その推論根拠が不明確であったために手術に踏み切れなかった結果、摘出すべき癌に対する治療の遅れにつながってしまったという事案が考えられます。
ポイント : 推論根拠を示すことができれば、その根拠の妥当性を基に適切な診断を下し迅速な治療を行うことができます。また、AIは誤った学習をしてしまうこともありますが、推論根拠が明確であれば学習の誤りにも気づくことができます。
金融機関の事例
AIによる与信審査で融資不可と審査されたが、その理由が不明確で、申請者は納得することができなかったとします。しかし後日、推論根拠を明らかにしてみたところ「申請者が女性であることを審査根拠としていた」ことが明らかになった場合、どのようなことが起こるでしょうか。これは明確に差別であり、重大な社会問題へと発展してしまいます。
ポイント : AIは特定の属性(人種、性別など)に基づいて不当な判断を下してしまう可能性もあるため、そのような変数は学習から除去していかなければなりません。
このように、推論根拠を可視化することは、AIの誤学習や偏りを防ぎ、安心して実務に活かすための重要な工程です。
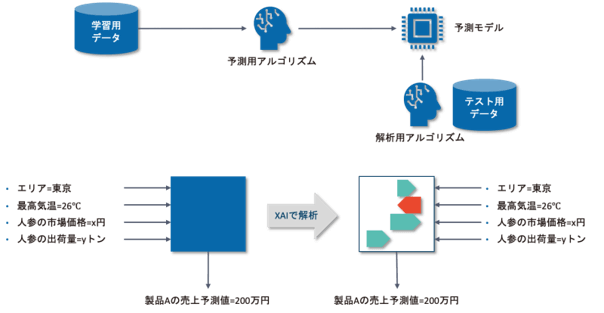
AIの推論根拠を可視化するXAIとは
XAI(Explainable AI:説明可能AI)とは、ブラックボックスになってしまっているAIの推論根拠を可視化するツールです。
代表的なXAIには、SHAP(シャップ)やLIME(ライム)、CAM(キャム)などがあります。XAIを適用することで推論根拠を可視化し、業務知見や専門知識の観点から「 AIの推論が結果だけでなくプロセスも含めて妥当なのか 」を確認でき、AIを実務に適用する、というところにより一層近づくことができます。
SHAPを活用した説明根拠の可視化事例
XAIの一つである SHAPによる説明根拠の可視化 の事例を紹介します。SHAPは、テストデータ全体の推論傾向を可視化することも、個別のテストデータの推論根拠を可視化することもできます。
タイタニック号の事例から見たXAIの機能
全体の推論傾向を可視化した事例で、有名なデータ分析コンペであるKaggleのイントロダクションとして実施される「タイタニック」の問題データを取り上げます。これは、タイタニック号の沈没事件で生存した方、生存できなかった方を、性別、チケットクラス、年齢、乗船した港など様々な属性から分類推論するという問題です。
推論モデルを作成した上で、SHAPに「この推論根拠を可視化して」と指示したのが次のグラフです。
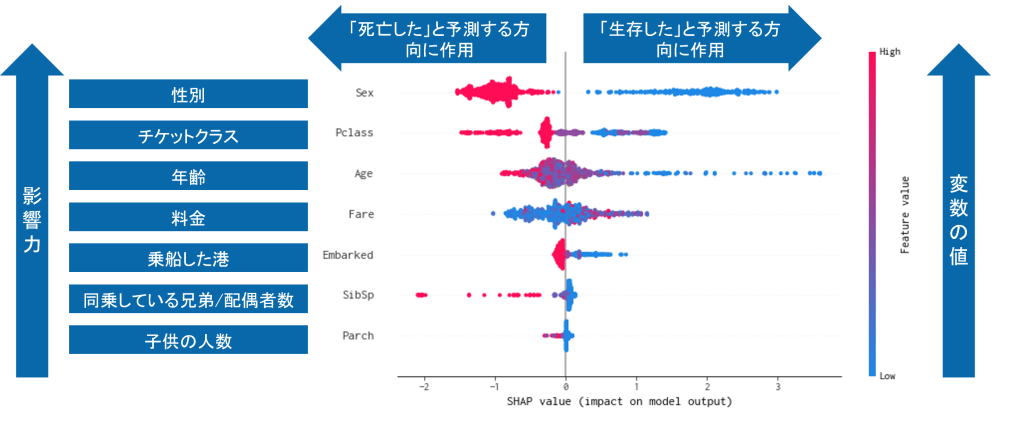
https://recruit.cct-inc.co.jp/wp-content/uploads/2019/01/treeshap_summary.png SHAPによるSummary_Plotの事例(KaggleのTitanicデータを使用)
図で上にある変数ほど影響力が大きいものになります。そのため、最も影響が大きい変数は 性別 、次が チケットクラス 、3番目に 年齢 となっています。
プロットの点一つ一つがデータ1個を表しており、そのデータにおける当該変数の値の大小を色で示してくれます。上図のプロットは、「女性である」「チケットクラスが高級である」「年齢が若い」ほど生存確率が高いと推論したことが読み取れます。これは、「女性と子どもを優先的にボートに乗せる救助方針であったこと」や「高級なチケットクラスほど救助ボートが設置されている船首に近く、救助されやすかったこと」といった歴史的事実とも一致しています。
このように、XAIはAIの判断が事実や常識と整合しているかを確認する手段として有効です。
また、SHAPでは、個別のデータごとの推論根拠も可視化できます。
タイタニックの事例で言えば、一人一人について可視化でき、例えば「9歳の男の子は子どもであることが生存率を押し上げた」といった具合に、要因を視覚的に確認できます。

https://recruit.cct-inc.co.jp/wp-content/uploads/2019/01/treeshap_force.png
この場合、結果としては出力値が1.58となっており、生存方向にかなり寄っています。AIが「生存確率が高い」と推論した人になります。青く左に矢印が向いているのが生存確率を引き下げる要素、赤く右に向いているのが生存確率を上げる要素を示しています。この人は、チケットクラスが低く、男性だったという要因が生存者である確率を下げてはいるものの、年齢が9歳である、つまり子供であるということが生存者である確率を大きく押し上げており、結果としてAIは「生存するだろう」と推論していることが分かります。
このように、「なぜAIはこのような判断をしたのか」について一件一件細かく見ることができ、テーブルデータでも確認することが可能です。
画像解析におけるXAIの活用事例
SHAPは画像解析にも適用可能です。下図は、被写体が城であるかどうかをAIに分類させた例です。

https://recruit.cct-inc.co.jp/wp-content/uploads/2019/01/castle.png
結果としては「城です」と分類しており、その推論根拠が赤の濃い部分で示されています。天守閣の屋根に沿った部分を見て、「この建物、この被写体は城だね」とAIが推論したことが見て取れます。
確かに、改めて「人はどこを見てこの建物を城と認識するだろうか」と考えてみると、確かに屋根の形や何階層にもなっている天守閣の形などは判断のポイントになると思います。AIも非常に人間に近い推論根拠のもとに、この建物を城と推論しているのだということが、この事例から分かります。
まとめ:AI活用における重要なポイント
AIを使うためには、 分析テーマ、データ、そして AIを使える環境 が揃っていることが必要です。これらは、AIに関する専門知識を持っていなくても、十分に整えることが可能です。
各要素のポイント
- テーマ : 適切なテーマを設定するには、「やりたいこと/解決したいこと」と「今手元にあるデータ」の双方から考えていきます。
- 環境 : AnacondaやKNIMEといったデータ分析ツールを導入すると、データの加工からAIを使った推論まで簡単に実施できます。また、アルゴリズムに迷った時にはチートシートを見て、自分に今適したアルゴリズムを辿っていくのがおすすめです。
- 推論根拠 : 推論根拠を明確化し、業務との照らし合わせをすることで、AIに対する信頼性を高め、現場での活用を促進できます。ただし、推論根拠の明確化については、テーマの設定やデータの整備に比べるとややハードルが高く、社内の詳しい方や外部のコンサルタントやデータサイエンティスト等にご相談いただくのが良いでしょう。
AI活用のご相談はNCDCへ
NCDCは、データ活用支援において豊富な実績を有しています。 例えば、ある食品メーカー様のプロジェクトでは、AIの予測根拠を可視化する「SHAP」を活用しました。
このお客様の社内では「気象変動と自社商品の市場動向には相関がある」と経験的に認識されていましたが、それは未実証の仮説に留まっていました。そこで私達は、過去のデータを収集・結合し、AIによる需要予測モデルを構築。さらに、SHAPを用いて「AIがなぜその予測に至ったのか」という根拠を可視化する支援を行いました。これにより、従来の「経験と勘」への依存から脱却し、データに基づく論理的な業務改革の推進をサポートしました。
SHAPなどにご興味のある方、あるいは「手元にデータはあるけれど、どう使うか悩んでいる」という方がいらっしゃいましたら、ぜひお気軽にご相談ください。